- 登入
- 註冊



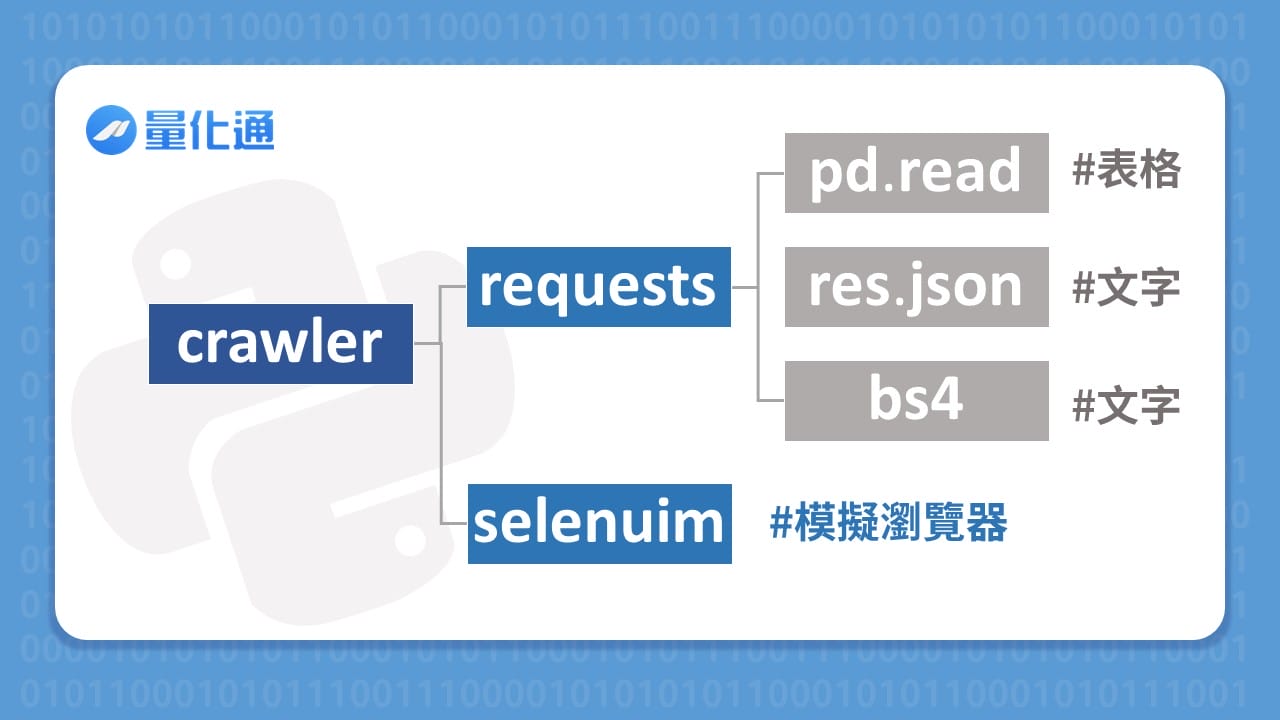
這個章節來到Python的最強功能【網頁爬蟲】,這也是數據分析最重要的前菜,大家想想看,要進行數據分析前最重要的是什麼?
當然就是要有數據,而數據的來源通常就是網路上公開的資料,但有些網站沒有提供下載的按鍵,這時候就要解析網頁結構去爬取我們想要的數據,最後將爬蟲寫成每日自動爬取,如此一來就可以進行數據分析的部分囉!


*贊助商內容

證交所網站連結:https://www.twse.com.tw/zh/

data為表格型態 ➨ pd.read
import pandas as pd
import requests
import io
# 將json改為csv
url = 'https://www.twse.com.tw/exchangeReport/MI_INDEX?response=csv&date=20220412&type=ALLBUT0999&_=1649743235999'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36'}
res = requests.get(url,headers=headers)
# 去除指數價格
lines = [l for l in res.text.split('\n') if len(l.split(',"'))>=10]
# 將list轉為txt方便用csv讀取
df = pd.read_csv(io.StringIO(','.join(lines)))
# 將不必要的符號去除
df = df.applymap(lambda s:(str(s).replace('=','').replace(',','').replace('"',''))).set_index('證券代號')
# 將數字轉為數值型態
df = df.applymap(lambda s:pd.to_numeric(str(s),errors='coerce')).dropna(how='all',axis=1)
df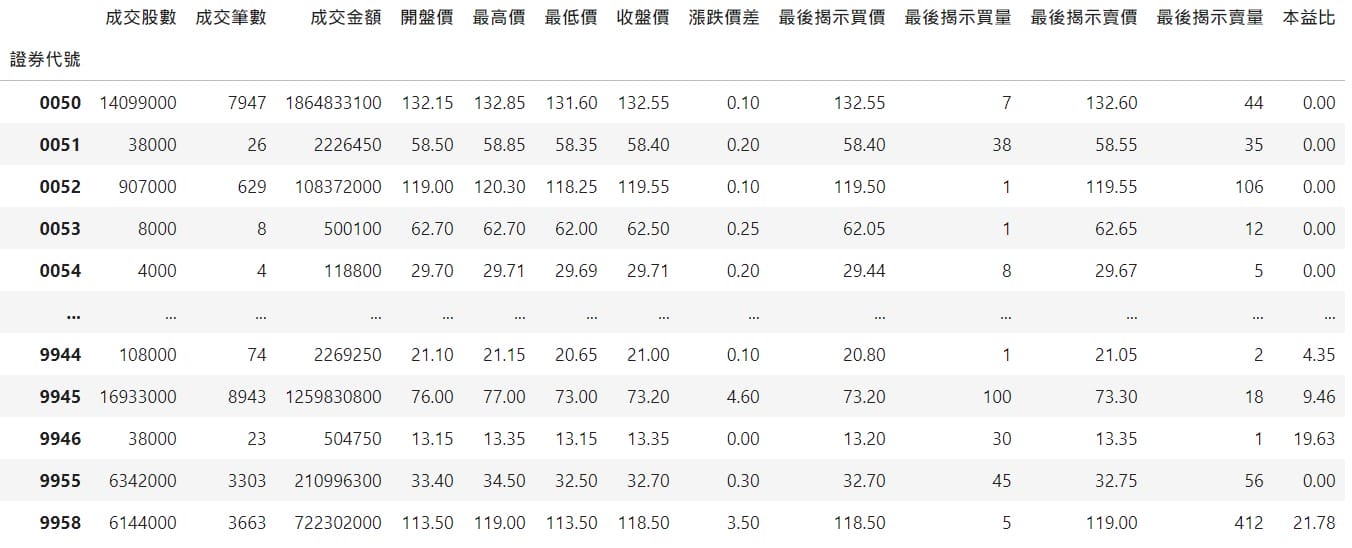
公開資訊觀測站網站連結:https://mops.twse.com.tw/mops/web/index
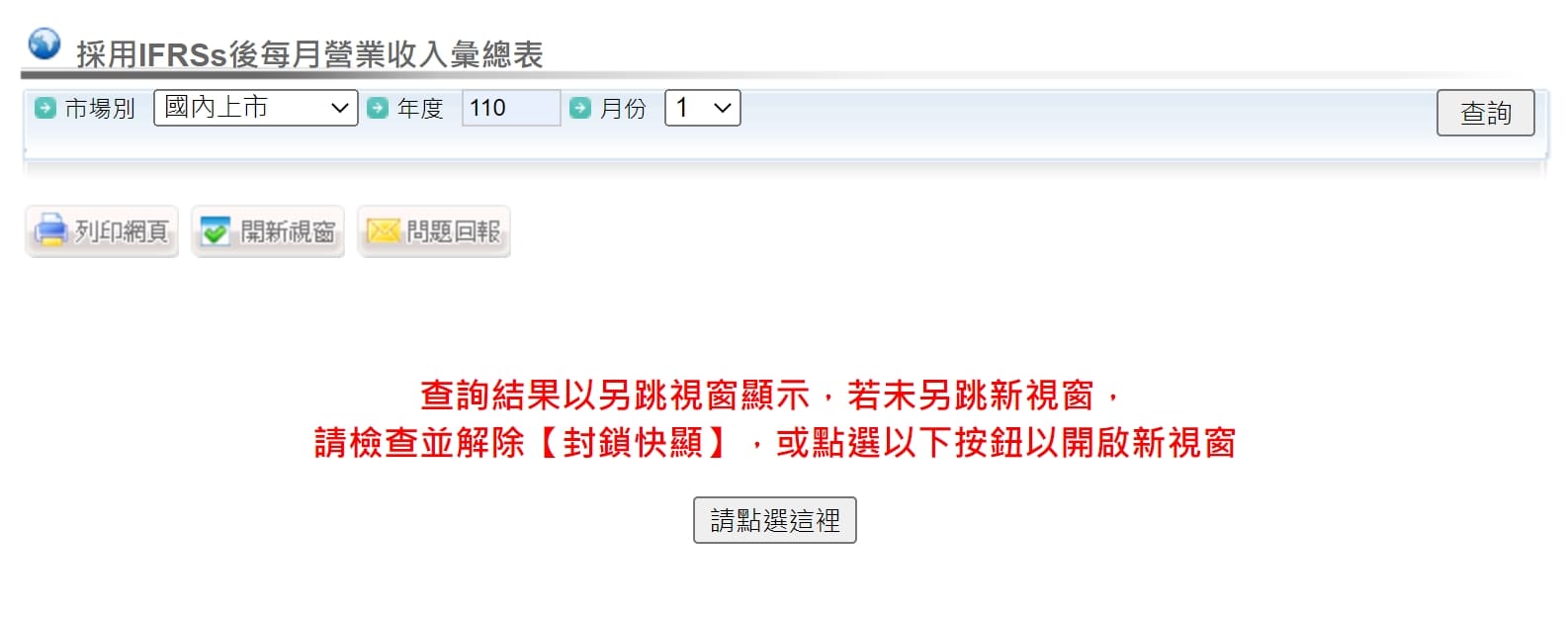
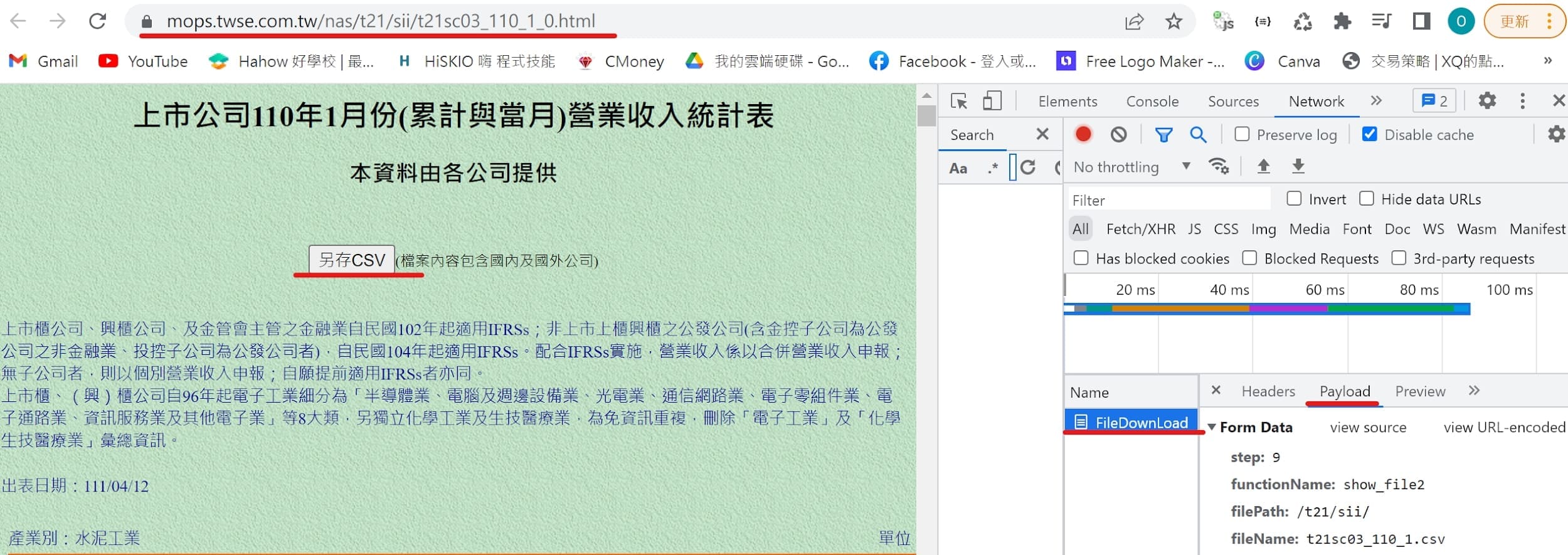
data為表格型態 ➨ pd.read
點選按鈕 ➨ payload
import pandas as pd
import requests
import io
url = 'https://mops.twse.com.tw/server-java/FileDownLoad'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36'}
payload = {
'step': '9',
'functionName': 'show_file2',
'filePath': '/t21/sii/', # otc
'fileName': 't21sc03_110_1.csv'
}
res = requests.post(url,data=payload,headers=headers)
res.encoding = 'utf8'
df = pd.read_csv(io.StringIO(res.text))
# 將不必要的符號去除
df = df.applymap(lambda s:str(s).replace(',','')).set_index('公司代號')
# 將數字轉為數值型態
df = df.applymap(lambda s:pd.to_numeric(str(s),errors='coerce')).dropna(how='all',axis=1)
df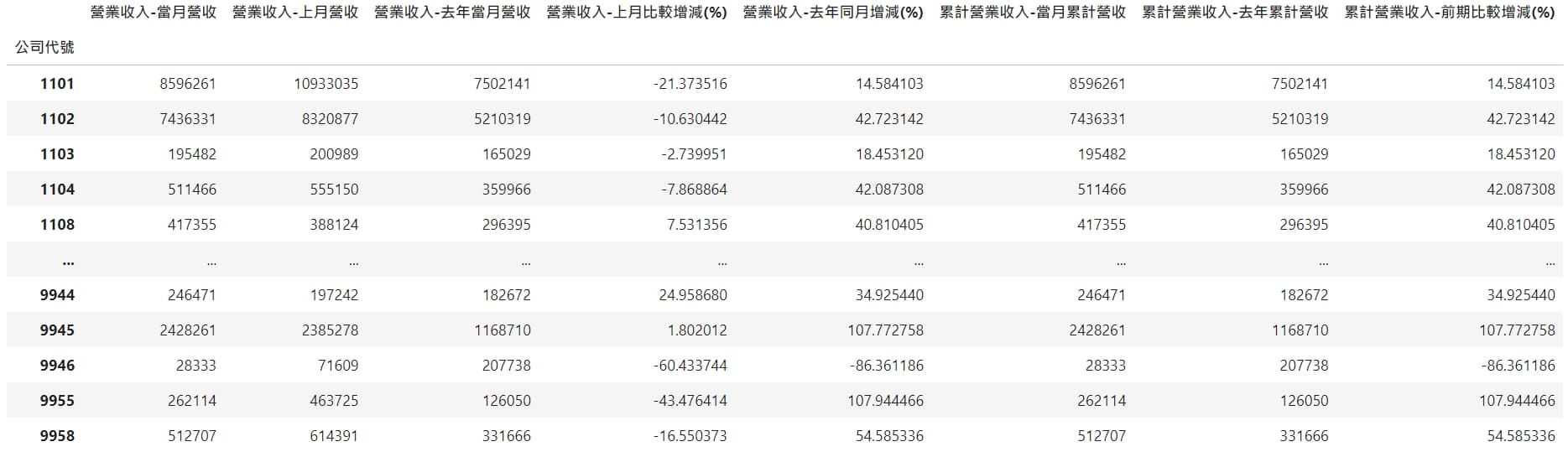
鉅亨網網站連結:https://www.cnyes.com/
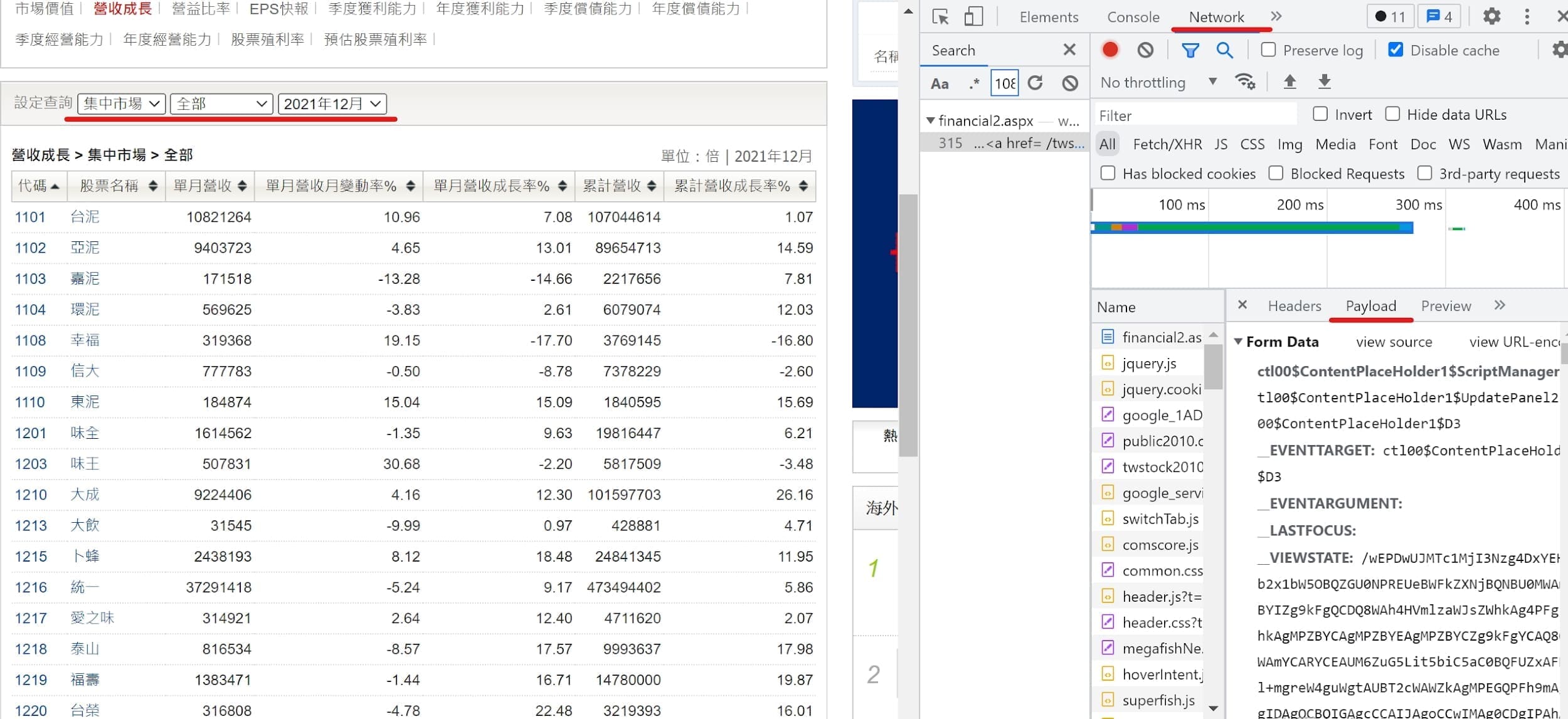
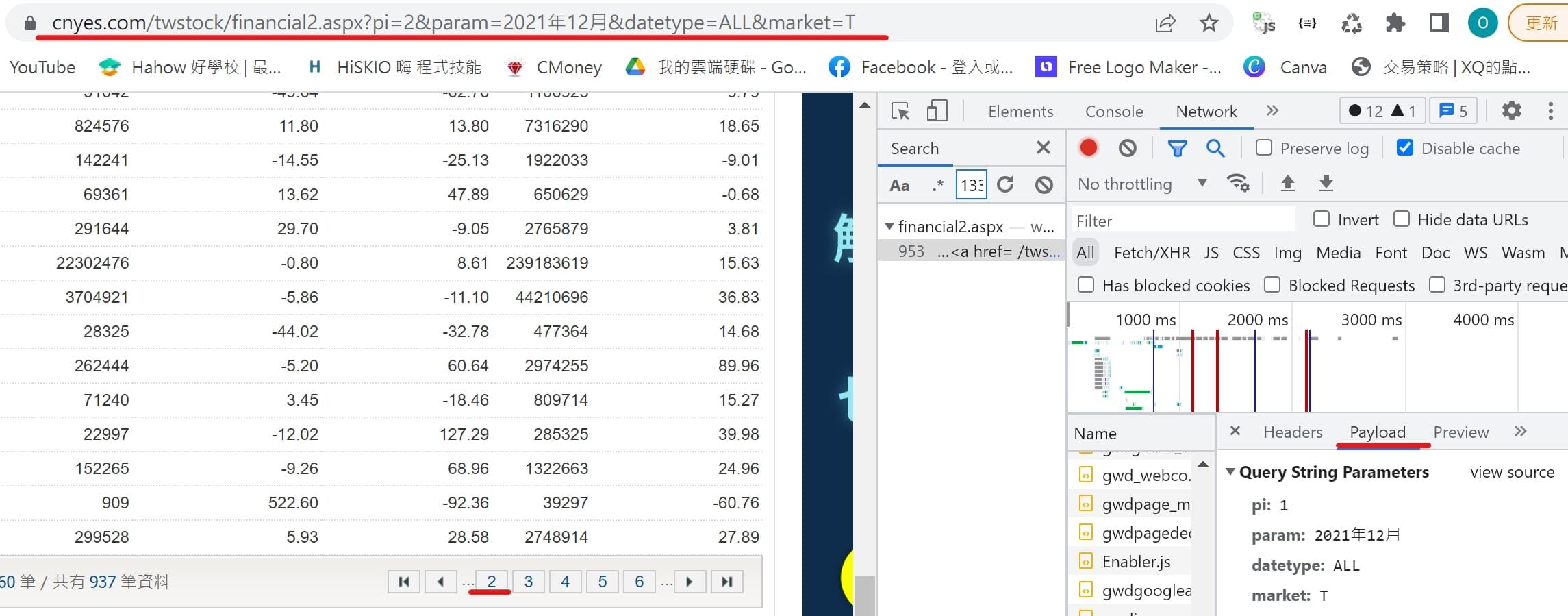
data為表格型態 ➨ pd.read
點選按鈕 ➨ payload
import pandas as pd
import requests
import io
dfs = pd.DataFrame()
# 將所有頁面的df組合
for page in range(1,50):
url = f"https://www.cnyes.com/twstock/financial2.aspx?pi={page}¶m=2021%E5%B9%B412%E6%9C%88&datetype=ALL&market=T"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36'}
payload = {
'pi': page,
'param': '2021年12月',
'datetype': 'ALL',
'market': 'T'
}
res = requests.post(url,data=payload,headers=headers)
df = pd.read_html(res.text,header=0)[0]
if df['代碼'][0] == '無相關資料':
break
dfs = dfs.append(df)
# 去除不必要的符號
dfs = dfs.applymap(lambda s:str(s).replace(',','')).set_index('代碼')
# 將數字轉為數值型態
dfs = dfs.applymap(lambda s:pd.to_numeric(str(s),errors='coerce')).dropna(how='all',axis=1)
dfs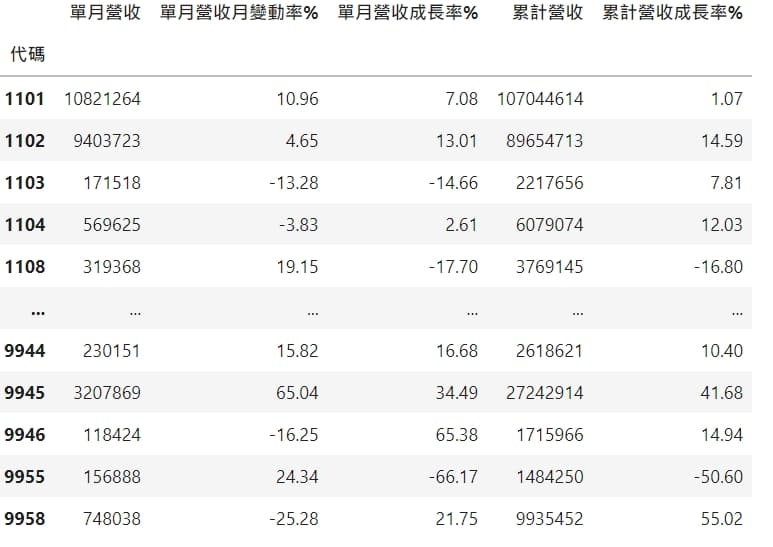
網頁爬蟲實戰的上半篇我們爬的網頁資料大多屬於表格(DataFrame)的形式,這代表通常我們只需要到 Network 內尋找向網站 requests 的 url 和 payload 就可以使用 pandas 套件內的功能去成功索取 data,但有些網站的資料看似使用表格去顯示但卻怎麼爬都爬不到怎麼辦呢?
這就代表我們需要解析網頁原始碼來一筆一筆 data 去做整理,想知道如何去爬這些惱人的網站嗎? 那就不要錯過爬蟲實戰,TradingView/CMoney/Yahoo finance-從零開始的Python股票爬蟲教學(四) !






