- 登入
- 註冊



這個章節要來解析如何爬取非表格型的網站資料或看似表格型但卻爬不到資料的狀況,這時候我們就會需要解析網頁的原始碼架構,查看資料會放在哪一個 class 內。
接著再一筆一筆去整理爬取到的 data,最後使用 pandas 內的 function 去將 data 組合成DataFrame!




*贊助商內容
data為非表格型態 ➨ BeautifulSoup or res.json
import pandas as pd
import requests
from bs4 import BeautifulSoup
import re
# 先取得各產業網址方便for迴圈爬蟲
url = 'https://tw.tradingview.com/markets/stocks-taiwan/sectorandindustry-industry/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36'}
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
dfs = pd.DataFrame()
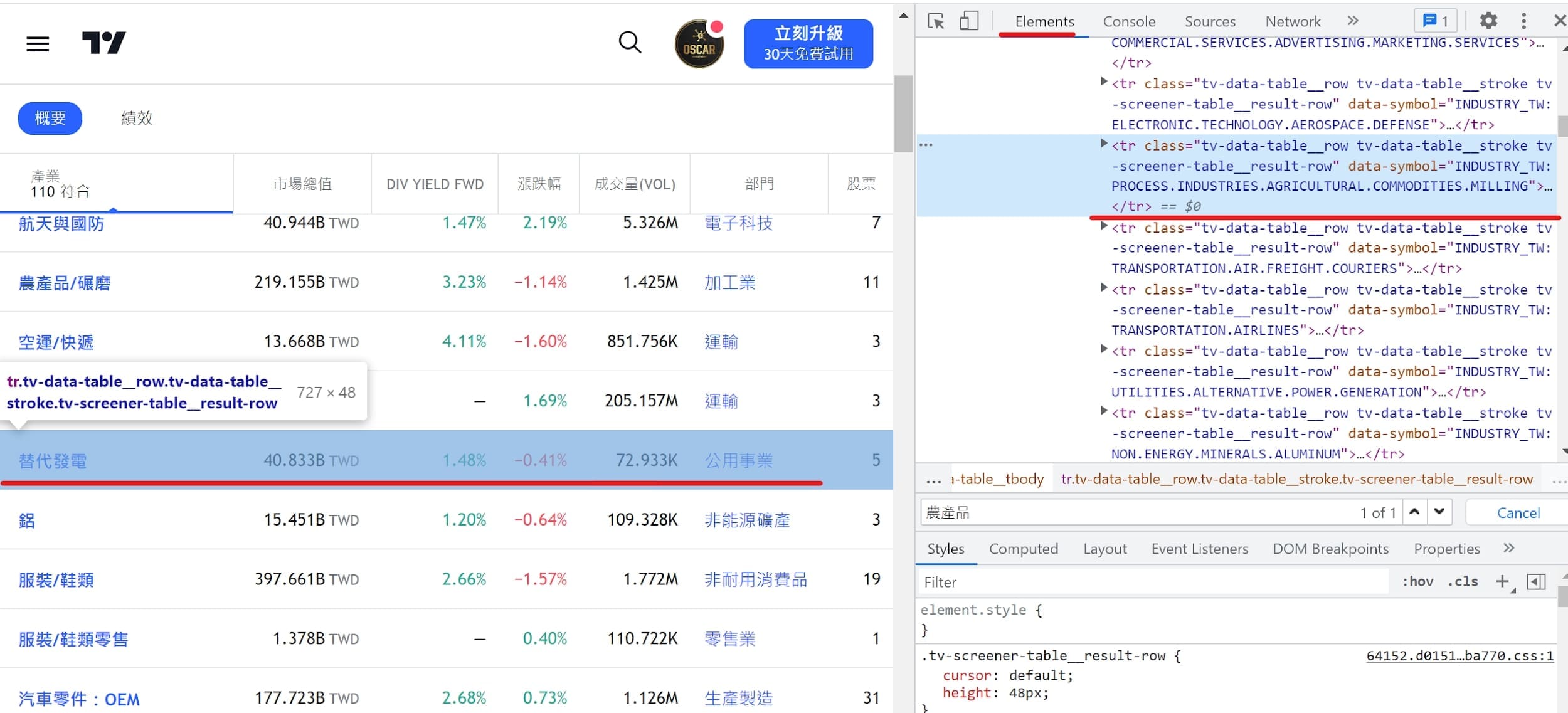
for line in soup.find_all(class_='tv-screener__symbol'):
# 取得各產業網址
href = 'https://tw.tradingview.com'+line['href']
industry = line.text
# 去除部門資料
if ('-sector' not in href)&('investment-trusts' not in href):
r = requests.get(href)
stocks = pd.read_html(r.text,header=0)[0].applymap(lambda s:str(s).replace(' ',''))['Unnamed: 0']
for sid in stocks:
# 處理股票代號格式
stock_id = ''.join([s for s in sid if s.isdigit()])
if len(stock_id)>4:
stock_id = stock_id[1:5]
# 使用re搜尋str中在stock_id後所有的文字
name = re.search(f"{stock_id}.*",sid).group()[4:]
dfs = dfs.append(pd.DataFrame({
'公司簡稱':name,
'產業族群':industry
},index=[stock_id]))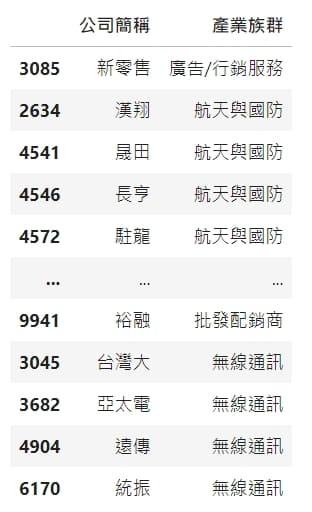
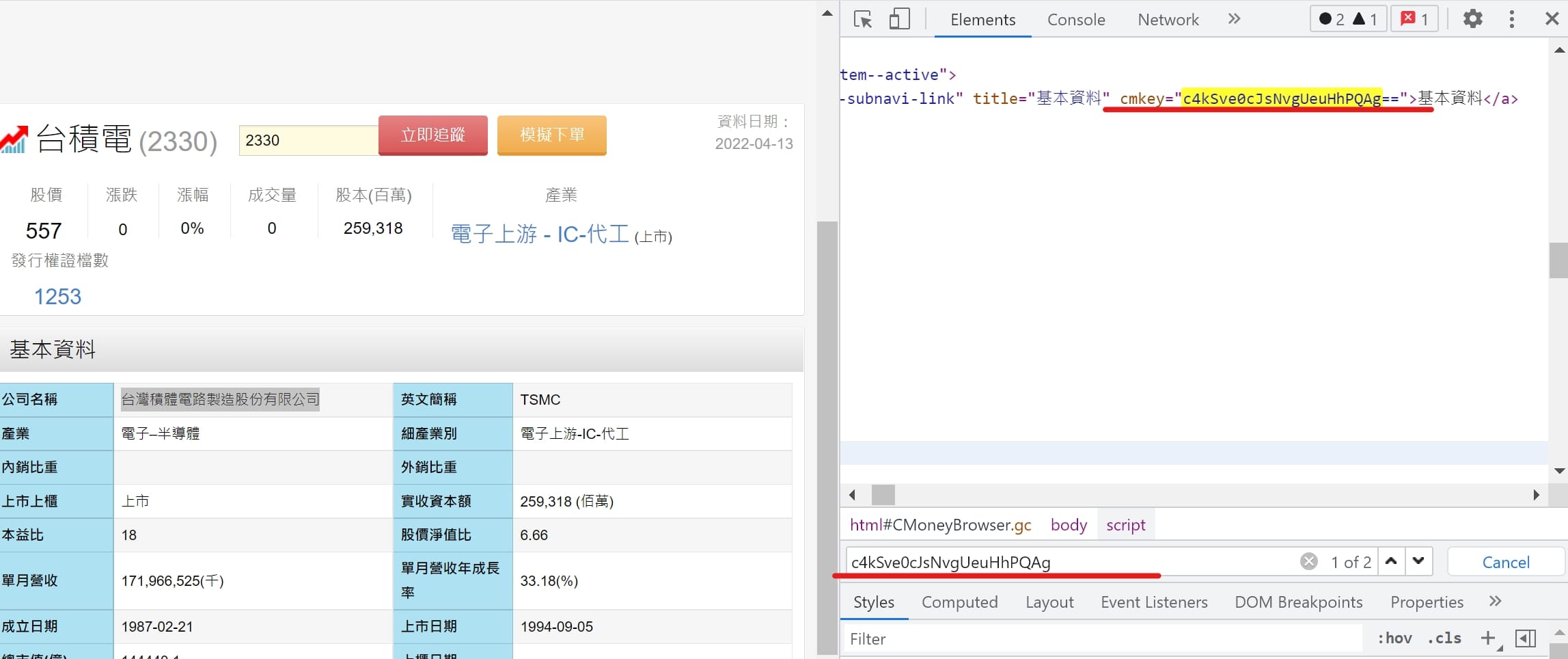
CMoney 網站連結:https://www.cmoney.tw/finance/2330/f00026
data為非表格型態 ➨ BeautifulSoup or res.json
爬蟲前需取得金鑰。
import pandas as pd
import requests
from bs4 import BeautifulSoup
import re
stock_id = '2330'
url = f"https://www.cmoney.tw/finance/f00026.aspx?s={stock_id}"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36'}
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
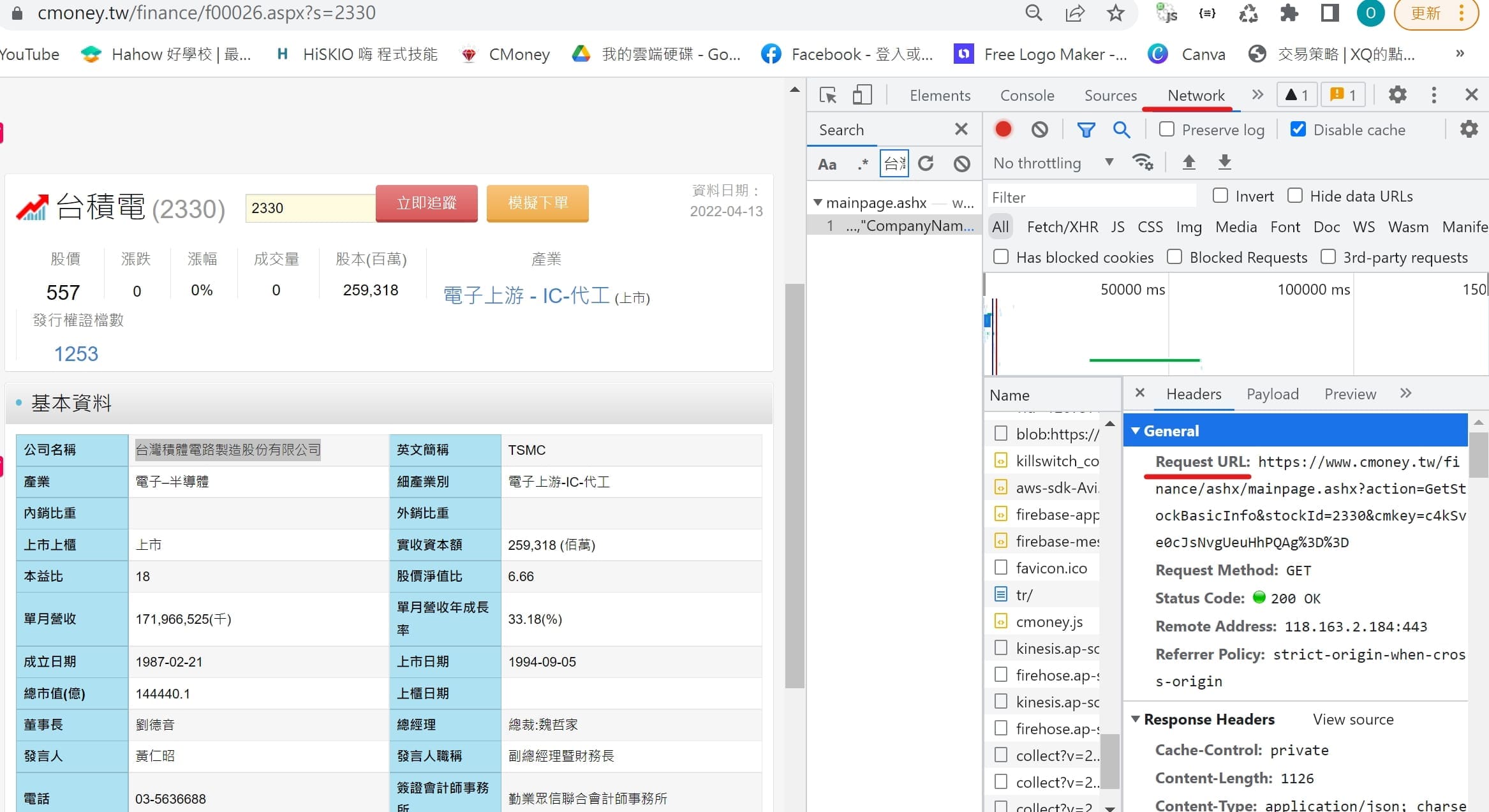
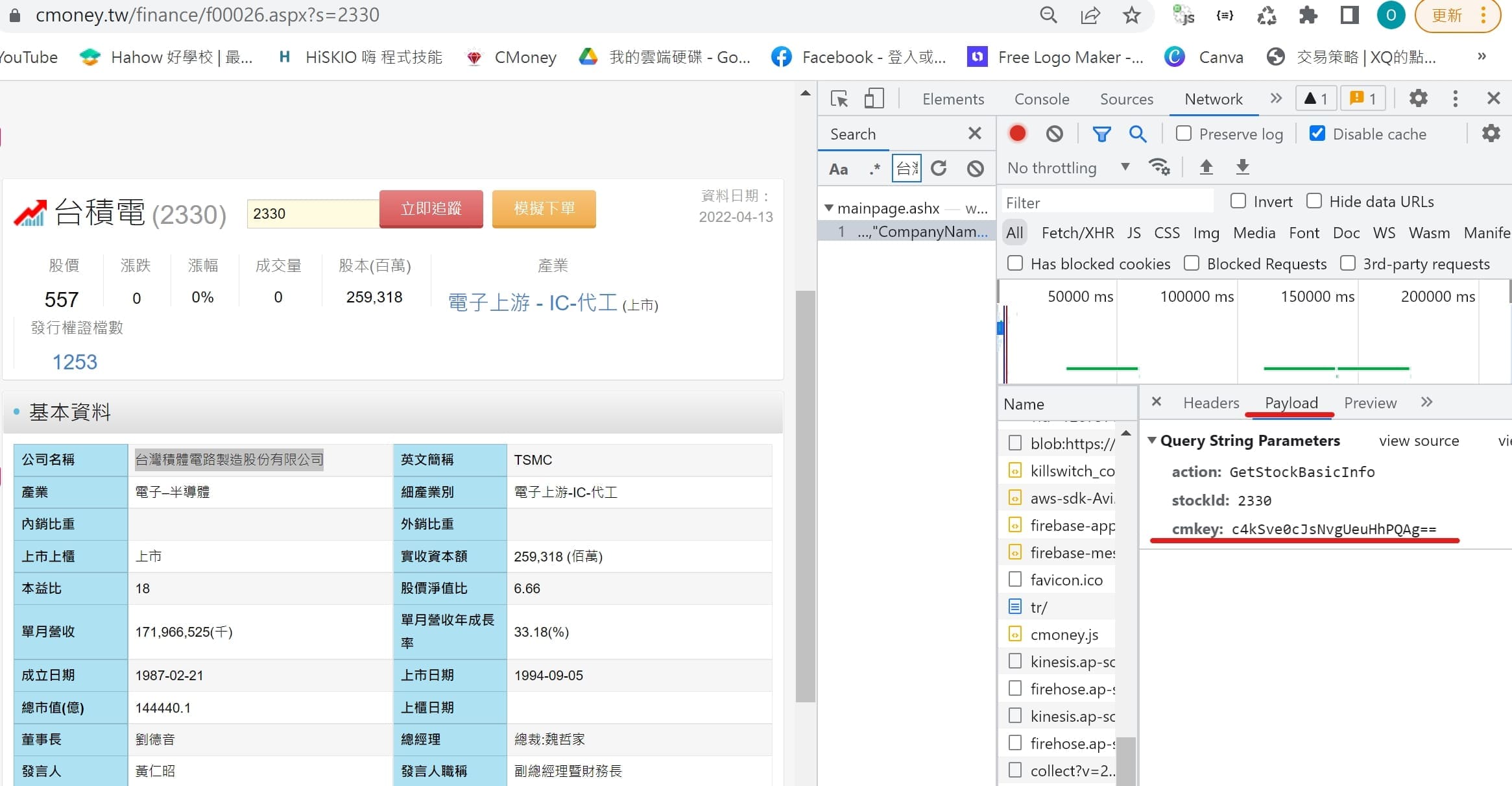
# 取得基本資料的cmkey
for line in soup.find_all(class_="mobi-finance-subnavi-link"):
if line.text == '基本資料':
cmkey = line['cmkey'].replace('=','%3D')
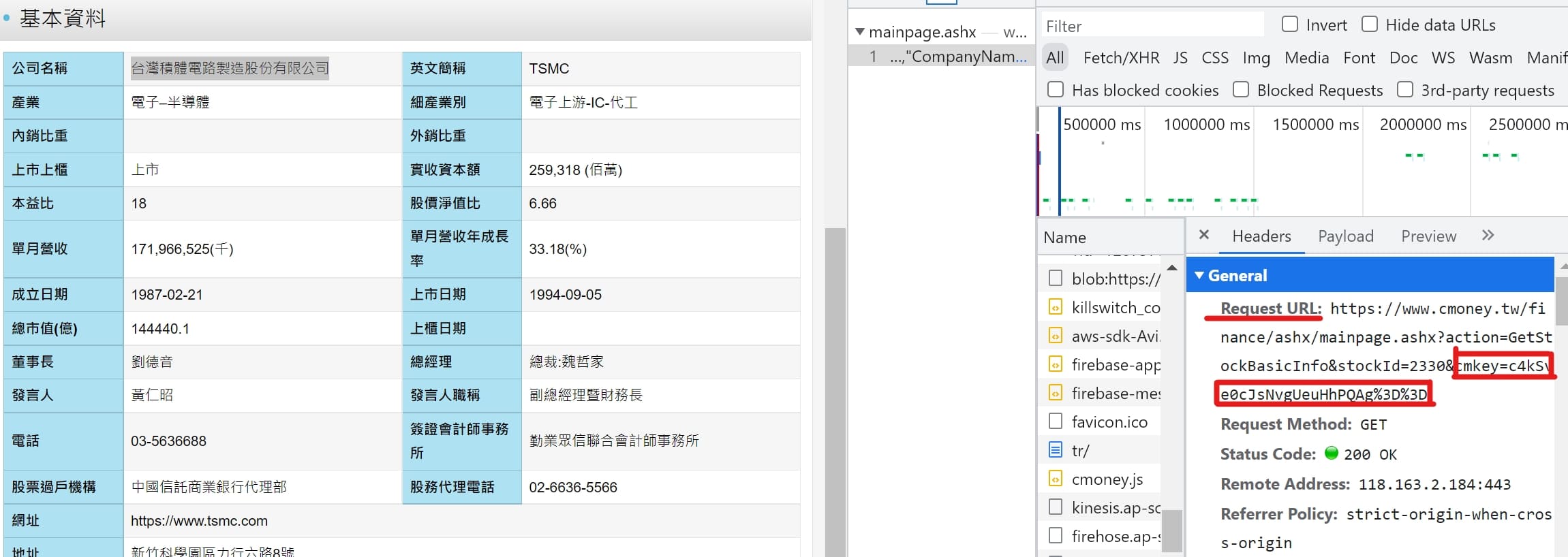
url = f"https://www.cmoney.tw/finance/ashx/mainpage.ashx?action=GetStockBasicInfo&stockId={stock_id}&cmkey={cmkey}"
# 特別注意要加入Referer
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36',
'Referer': f"https://www.cmoney.tw/finance/f00026.aspx?s={stock_id}"
}
res = requests.get(url,headers=headers)
data = res.json()[0]
df = pd.DataFrame({
'公司名稱':data['CompanyName'],
'產業':data['Industry'],
'細產業':data['SubIndustry'],
'經營項目':data['Business']
},index=[stock_id])
df
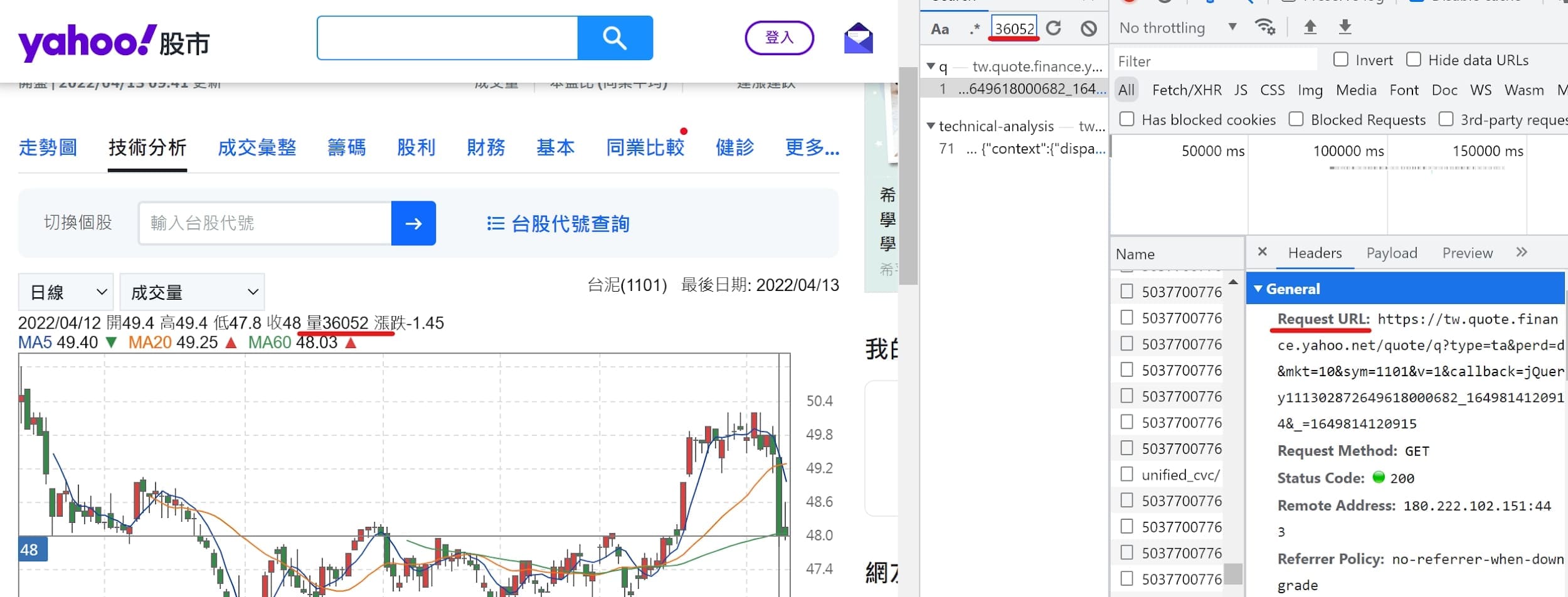
Yahoo即時報價網站連結:https://tw.stock.yahoo.com/
data為非表格型態 ➨ BeautifulSoup or res.json
import pandas as pd
import requests
from bs4 import BeautifulSoup
import re
stock_id = '2330'
url = f"https://tw.quote.finance.yahoo.net/quote/q?type=ta&perd=d&mkt=10&sym={stock_id}&v=1&callback=jQuery111302872649618000682_1649814120914&_=1649814120915"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/111.25 (KHTML, like Gecko) Chrome/99.0.2345.81 Safari/123.36'}
res = requests.get(url,headers=headers)
# 最新價格
current = [l for l in res.text.split('{') if len(l)>=60][-1]
current = current.replace('"','').split(',')
# 昨日價格
yday = float(re.search(':.*',[l for l in res.text.split('{') if len(l)>=60][-2].split(',')[4]).group()[1:])
df = pd.DataFrame({
'open':float(re.search(':.*',current[1]).group()[1:]),
'high':float(re.search(':.*',current[2]).group()[1:]),
'low':float(re.search(':.*',current[3]).group()[1:]),
'close':float(re.search(':.*',current[4]).group()[1:]),
'volume':float(re.search(':.*',current[5].replace('}]','')).group()[1:]),
'pct':round((float(re.search(':.*',current[4]).group()[1:])/yday-1)*100,2)
},index=[stock_id])
df
這兩篇的 Python 爬蟲示範有大大提升大家對於爬蟲網站數據的技巧了(吧?),其實市面上的爬蟲課程差不多只有教到證交所、公開資訊觀測站而已,至於鉅亨網、CMoney 目前還沒有課程在教,甚至即時報價大部分的人都是去爬基本市況報導。
但基本市況報導網站爬的速度偏慢,反而Yahoo的走勢圖股價蠻即時的,所以我們選擇Yahoo來爬即時報價。
而市面上爬蟲課程(爬證交所、財報)的價格幾乎都是6000元起跳,所以學到這篇的技巧等於是賺到翻掉啊XD,這篇教學文章也會不定期更新,未來如果有發現資料完整的網站也會將程式碼放上來提供大家學習!






