- 登入
- 註冊







*贊助商內容
與 web 互動上,在 python 中都是用 requests 為主要套件。透過 requests 可以對 HTTP 發送請求,抓取網頁的資料。因為它目前不是 python 預設套件,所以我們開始前需要先安裝:
pip install requests在 request 使用上主要分成兩種邏輯:get/post。(雖然還有 Put、Delete、 head…等,但本文先以常見的這兩種為主要介紹)
get 的邏輯是對網頁提出一個請求,這類的請求細節又大概分兩種:「不帶條件的」和「有帶條件的」。
通常網址很單純,就是個 https:// xxx 然後就沒了,這類的大概都是一些狀態確認或是基礎資料而已,以全世界最大的幣安交易所為例,取得最簡單的交易所資訊就可以直接打他們 API。
# 後面json表示用json解析後回傳
print(requests.get(url="https://api.binance.com/api/v3/exchangeInfo").json()) 結果如下
...False, 'filters': [{'filterType': 'PRICE_FILTER', 'minPrice': '0.00100000', 'maxPrice': '10000.00000000', 'tickSize': '0.00100000'}, {'filterType': 'PERCENT_PRICE', 'multiplierUp': '5', 'multiplierDown': '0.2', 'avgPriceMins': 5}, {'filterType': 'LOT_SIZE', 'minQty': '0.10000000', 'maxQty': '90000.00000000', 'stepSize': '0.10000000'}, {'filterType': 'MIN_NOTIONAL', 'minNotional': '10.00000000', 'applyToMarket': True, 'avgPriceMins': 5}, {'filterType': 'ICEBERG_PARTS', 'limit': 10}, {'filterType': 'MARKET_LOT_SIZE', 'minQty': '0.00000000', 'maxQty': '7317.16184850', 'stepSize': '0.00000000'}, {'filterType': 'TRAILING_DELTA', 'minTrailingAboveDelta': 10, 'maxTrailingAboveDelta': 2000, 'minTrailingBelowDelta': 10, 'maxTrailingBelowDelta': 2000}, {'filterType': 'MAX_NUM_ORDERS', 'maxNumOrders': 200}, {'filterType': 'MAX_NUM_ALGO_ORDERS', 'maxNumAlgoOrders': 5}], 'permissions': ['SPOT']}]}往往我們要的可能不止基本資料,會對需要的對方稍微提出一些基本需求,這時候就得靠下一個了:
url = "https://api.binance.com/api/v3/exchangeInfo?symbol=BNBBTC"
print(requests.get(url=url).json())
"""
結果:
{"timezone":"UTC","serverTime":1654293535998,"rateLimits":[{"rateLimitType":"REQUEST_WEIGHT","interval":"MINUTE","intervalNum":1,"limit":1200},{"rateLimitType":"ORDERS","interval":"SECOND","intervalNum":10,"limit":50},{"rateLimitType":"ORDERS","interval":"DAY","intervalNum":1,"limit":160000},{"rateLimitType":"RAW_REQUESTS","interval":"MINUTE","intervalNum":5,"limit":6100}],"exchangeFilters":[],"symbols":[{"symbol":"BNBBTC","status":"TRADING","baseAsset":"BNB","baseAssetPrecision":8,"quoteAsset":"BTC","quotePrecision":8,"quoteAssetPrecision":8,"baseCommissionPrecision":8,"quoteCommissionPrecision":8,"orderTypes":["LIMIT","LIMIT_MAKER","MARKET","STOP_LOSS_LIMIT","TAKE_PROFIT_LIMIT"],"icebergAllowed":true,"ocoAllowed":true,"quoteOrderQtyMarketAllowed":true,"allowTrailingStop":true,"isSpotTradingAllowed":true,"isMarginTradingAllowed":true,"filters":[{"filterType":"PRICE_FILTER","minPrice":"0.00000100","maxPrice":"100000.00000000","tickSize":"0.00000100"},{"filterType":"PERCENT_PRICE","multiplierUp":"5","multiplierDown":"0.2","avgPriceMins":5},{"filterType":"LOT_SIZE","minQty":"0.00100000","maxQty":"100000.00000000","stepSize":"0.00100000"},{"filterType":"MIN_NOTIONAL","minNotional":"0.00010000","applyToMarket":true,"avgPriceMins":5},{"filterType":"ICEBERG_PARTS","limit":10},{"filterType":"MARKET_LOT_SIZE","minQty":"0.00000000","maxQty":"13613.81240931","stepSize":"0.00000000"},{"filterType":"TRAILING_DELTA","minTrailingAboveDelta":10,"maxTrailingAboveDelta":2000,"minTrailingBelowDelta":10,"maxTrailingBelowDelta":2000},{"filterType":"MAX_NUM_ORDERS","maxNumOrders":200},{"filterType":"MAX_NUM_ALGO_ORDERS","maxNumAlgoOrders":5}],"permissions":["SPOT","MARGIN"]}]}
"""get 的類型通常在爬蟲上很常用,因為爬蟲往往比較少會需要帶個人資料,但是進階一點的動態網頁,可能就很難單純只用網址就可以取得相關資料,故這時候也可能會需要對於其網頁進行一些研究與分析。
而上述例子中,連接在網址後面的 「?symbol=BNBBTC」就是所謂的 query,這類相當於我們送請求給網站或是對應的 API 時,跟他們說一些篩選條件,但這類的做法並不適合將一些私人安全金鑰等等的資訊帶在網址上一起給。
所以就有了安全性較高的另一種作法:post。
以下以取得期交所的資料為範例:
觀察期交所網站會發現:https://www.taifex.com.tw/cht/3/totalTableDate
它更改日期並沒有讓網址變動,這時候就得去找對應的網頁api了,若是當日資料,我們能輕易取得。如果是歷史資料,該怎麼操作呢?
下列的案例帶大家操作一遍取得特定日期資料的方式,即使是歷史資料,也能順利爬出資料。
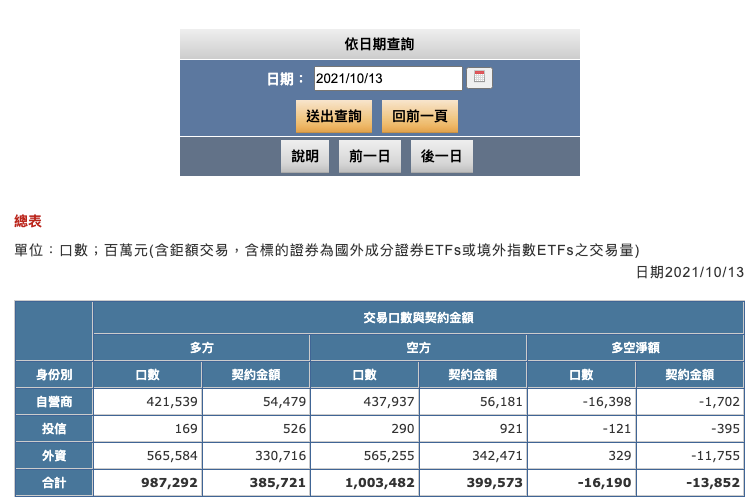
預計取得2021/10/13資料,按下 F12 找到 Network。
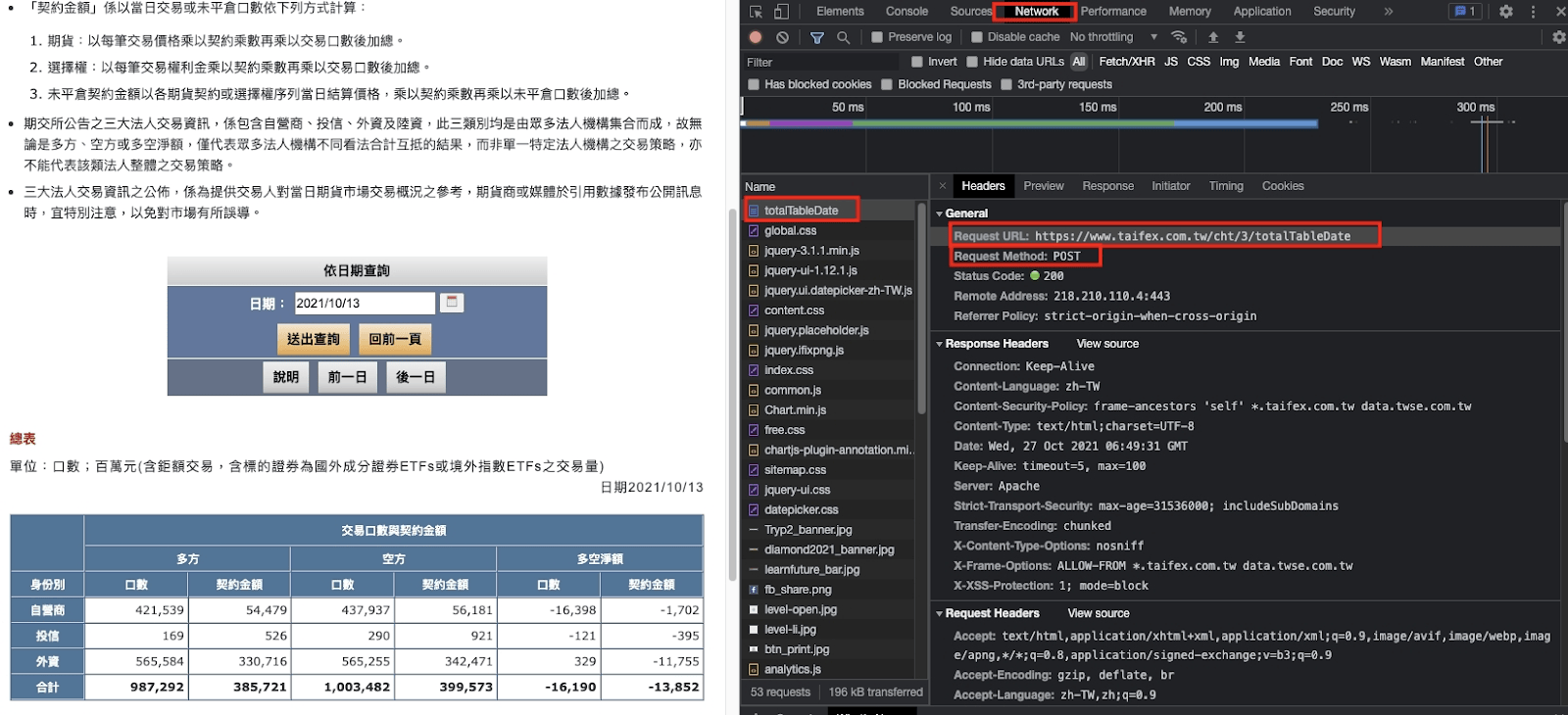
下圖中可以發現,在這裡無法顯示歷史數據,因此要用「post」取得過往資料。拉到底下找需要運用的資料。
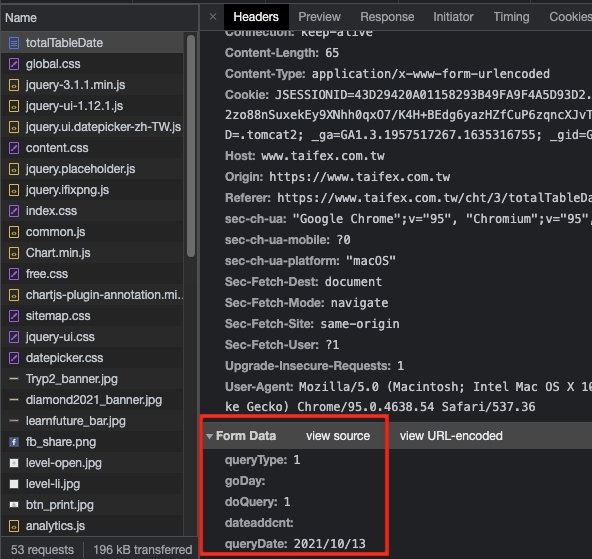
上圖的紅框處就是我們需要的 code。
url = 'https://www.taifex.com.tw/cht/3/totalTableDate'
payload = {
'queryType': 1,
'goDay': '',
'doQuery': 1,
'dateaddcnt': '',
'queryDate': "2021/10/16",
}
res_json = requests.post(url, payload)
soup = BeautifulSoup(res_json.content, 'html.parser').find_all('table')
print(soup)因為爬蟲的做法在其他文章提到過囉,這邊就不重新解釋,輸入以上程式碼就能取得相關資料。
至於內部資料的處理,資料處理的邏輯都是一樣的,可以根據自己的需求,參考前面章節提到方法做整理囉!
基本上可以切成:
這三種方式,去與網頁們互動,隨著各位的能力提升,會發現爬蟲很多時候只是一個手段,更即時、更大量、更精確的資料,都會需要去讀每間公司的 API文件。
他們對於API還會有 header加密帶私鑰的安全作法,這類型的任務往往表示這些是對方公司開出來給大家用的,適合更高頻率、高需求的使用情境,而這種類型的資料往往也會是需要被大量分析的囉!
掌握 get、post 的概念後,未來還有 session. websockets 類的交互方式等著各位去學習與發掘!這篇大概就到這邊囉!如果有任何心得或是想討論的歡迎於底下留言!謝謝大家!






