- 登入
- 註冊







*贊助商內容
恭喜各位撐到這章節,這章節會稍微輕鬆一些,比較偏理論的理解,就讓我們馬上開始吧!
很多人可能會很好奇,這個操作的功能是什麼呢?在資料處理的過程中,很常會遇到資料不見、缺失、異常等情形。當有資料缺失就難以分析,因此需要先處理有問題的資料,才有辦法分析。
以下會用到「numpy」套件,一樣我們先透過 Pycharm 左下方的 Terminal pip install numpy。
「numpy」是 Python 中對於資料處理更講求效能的套件,也相對更難,因此在這部分用到的功能只是產生 NaN,並不是「numpy」套件的操作方式。
先創建一份資料,並轉成 DataFrame:
import pandas as pd
import numpy as np
df = pd.DataFrame(
[
[np.nan, 2, np.nan, 0],
[3, 4, 6, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]
],
columns=list('ABCD')
)
print(df)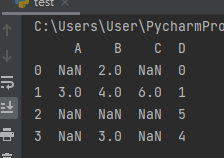
邏輯上是先填補缺失值,再使用某些方式填進數值。以下會示範幾種方式,不表示這是最正確的做法。
各種資料填補方式與需求都不一樣,有些缺漏的資料缺了就是缺了,不應該被填補,因此應該根據每項資料與需求,決定如何填充與處理缺漏資料。
# 刪掉 NaN的對應的 colume、row,只留下資料完整的表格
clean = df.dropna()
print(clean)
# 以0填補
nadf = df.fillna(0)
print(nadf)
#以-999填補
df99 = df.fillna(-999)
print(df99)
# 以該欄位所有資料的算術平均數做填補
mean_df = df.fillna(df.A.mean())
print(mean_df)
#以該欄位所有資料的中位數做填補
med = df.fillna(df.median())
print(med)直接看結果比較清楚喔!
# df.dropna() 的結果
A B C D
1 3.0 4.0 6.0 1
# df.fillna(0) 的結果
A B C D
0 0.0 2.0 0.0 0
1 3.0 4.0 6.0 1
2 0.0 0.0 0.0 5
3 0.0 3.0 0.0 4
# df.fillna(-999) 的結果
A B C D
0 -999.0 2.0 -999.0 0
1 3.0 4.0 6.0 1
2 -999.0 -999.0 -999.0 5
3 -999.0 3.0 -999.0 4
# df.fillna(df.A.mean()) 的結果
A B C D
0 3.0 2.0 3.0 0
1 3.0 4.0 6.0 1
2 3.0 3.0 3.0 5
3 3.0 3.0 3.0 4
# df.fillna(df.median()) 的結果
A B C D
0 3.0 2.0 6.0 0
1 3.0 4.0 6.0 1
2 3.0 3.0 6.0 5
3 3.0 3.0 6.0 4整理 DataFrame 的方法有很多,包含新增、修改、取得、刪除、篩選和排序資料等,最常見的使用方法有很多程式都能做到,但 pandas 的功能非常多,隨著使用情境的不同,功能也會不一樣,
因此藉由整理 DataFrame,帶大家熟練 Python 常見的功能、套件、語法與基本使用情境。
首先先上個假設的數據,Datetime 可以看出來是字串格式(有那個 _ 表示字串)。
df = pd.DataFrame(
{
'data1': [1, 2, 3],
'data2': [4, 5, 6],
'Datetime': ['2022/06/04_04:54:28', '2022/06/03_04:54:28', '2022/06/02_04:54:28'],
}, index=['A', 'B', 'C']
)這種在很多爬蟲的資料中都是長成各類字串格式的時間,所以讓 pandas 統一處理即可:
df['Datetime'] = pd.to_datetime(df['Datetime'], format="%Y/%m/%d_%H:%M:%S") # 處理有 "_" 的字串# 結果
data1 data2 Datetime
A 1 4 2022-06-04 04:45:00
B 2 5 2022-06-03 04:45:00
C 3 6 2022-06-02 04:45:00有個更快速的方法,在數據量大的時候可以使用,速度大概差 60% 以上:
df['Datetime'] = df['Datetime'].apply(lambda index: datetime.strptime(index,"%Y/%m/%d_%H:%M:%S"))此做法甚至比原先內建套件的還快上許多,但程式碼就相對難理解一點,就看情境的取捨囉!
先產一份簡易的隨機數據:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(8, 4) * 5)
print(df)
"""
結果:
0 1 2 3
0 0.434992 1.735385 1.824147 2.596633
1 0.960645 1.693874 3.945142 3.782143
2 2.820359 3.641548 2.414748 2.421735
3 0.373806 1.950452 3.706840 3.570724
4 2.340742 4.951858 1.253499 1.179138
5 0.839368 1.956993 1.279751 0.020432
6 4.838943 1.721855 4.860754 1.813471
7 3.478803 1.774799 2.179204 1.000244
"""這類情境在爬蟲時也很常遇到,很多表格以為是數據,結果做完發現他是字串,但有時候是整份 csv 直接爬下來,不太適合邊爬邊處理數據時,不如就用這功能直接做轉換吧!
print(df.astype(int))
"""
結果:
0 1 2 3
0 0 4 1 0
1 1 1 2 2
2 2 4 3 3
3 3 1 4 0
4 3 1 2 0
5 2 3 2 3
6 2 2 1 4
7 4 1 4 3
"""可是雖然轉成了int,但其實直接轉成整數的話,會失去一些操作的空間,這時候就可以進階的使用 round 做四捨五入囉,當然,可以轉成 int 當然就可以轉回來囉:
# 用四捨五入正式處理一下數據
print(df.astype(int))
print("==============")
# 轉回來
new_df = df.astype(int)
print(new_df.astype(float))馬上看一下結果:
0 1 2 3
0 0 2 1 0
1 0 1 2 3
2 1 2 0 1
3 1 2 2 2
4 1 3 4 3
5 0 1 3 3
6 3 2 2 1
7 1 3 2 1
==============
0 1 2 3
0 0.0 2.0 1.0 0.0
1 0.0 1.0 2.0 3.0
2 1.0 2.0 0.0 1.0
3 1.0 2.0 2.0 2.0
4 1.0 3.0 4.0 3.0
5 0.0 1.0 3.0 3.0
6 3.0 2.0 2.0 1.0
7 1.0 3.0 2.0 1.0一般而言,最常用的輸出格式便是 csv,可是針對其輸出方式也有一些常用的調整參數。使用上面的new_df當成輸出數據:
# 最簡易的輸出方式
new_df.to_csv("test_doc_1.csv")
# 可以選擇不要把 index 寫入csv
new_df.to_csv("test_doc_2.csv", index=False)
# DataFrame 寫入 CSV 時,預設是用逗號分隔。但如果某些條件下導致我們不能用逗號,則可以使用 sep 參數指定分隔符號。
new_df.to_csv("test_doc_3.csv", index=False, sep="\t")結果便會有三份 csv囉,我們終於大功告成啦!
基本上這邊比較偏向於情境理解與基本操作,下一章節就是最後一章囉!大家加油!
如果有任何想要討論的,都歡迎底下留言!






