- 登入
- 註冊


如果想用 AI 做 AI 程式交易策略研發,前提其實不是先選模型,而是先把需要的資料與流程準備完整。
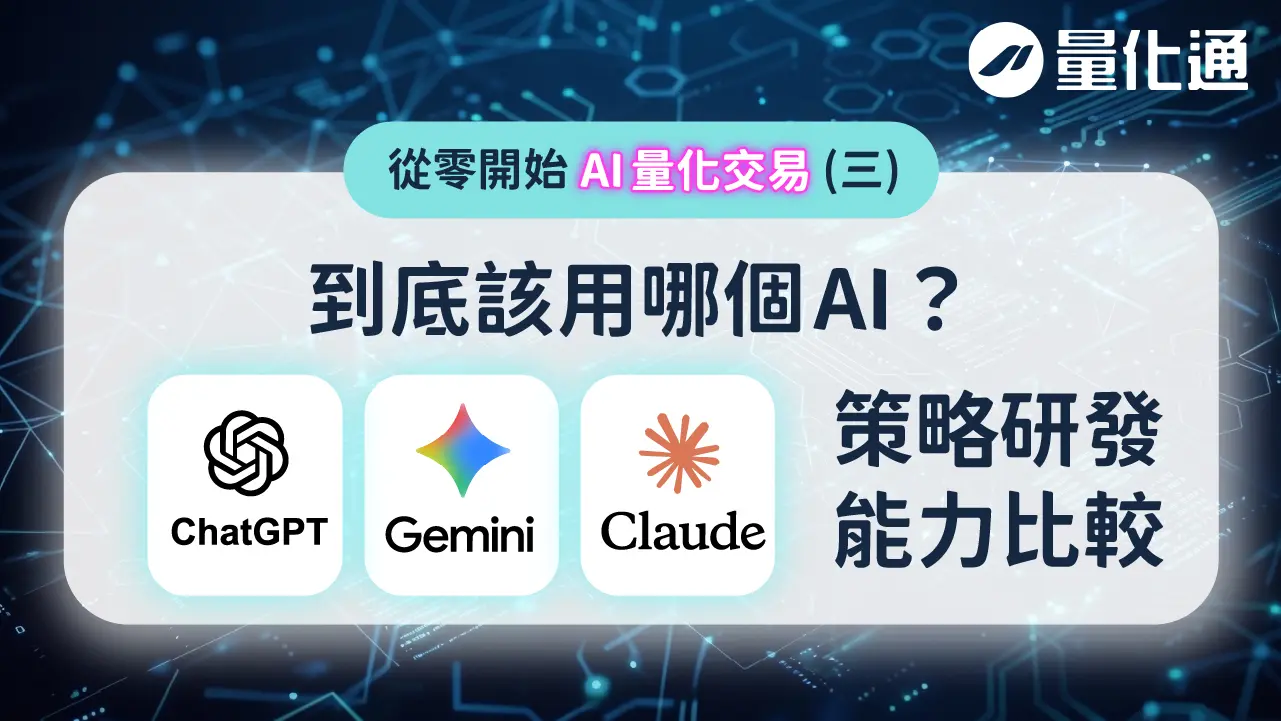
基本上至少要有平台語法資料、交易市場的 K 棒資料,以及一套能反覆驗證的策略研發架構。後面的工作才會進入策略蒸餾、邏輯拆解、停損停利 設計、濾網加入與參數最佳化。




*贊助商內容
這篇文章會先整理目前三大主流 AI 工具在本地端開發上的應用方式,再把我自己實際用在 XQ 策略研發上的流程與比較結果一併記錄下來。
這次我們把龍蝦 OpenClaw 先暫時放在一旁,我們先來看看目前三大主流 AI 在策略研發上的應用方式。
延伸閱讀:
•5分鐘搞定龍蝦安裝,OpenClaw 與 Telegram串接
•用 AI 量化交易前必知的坑!前導教學與避雷指南
如果你想利用 AI 進行程式交易策略的研發,在開始之前,至少需要準備三種核心資料:
例如官方說明文件、語法手冊,或是 GitHub 上的範例程式碼。
也就是你要研究的商品歷史資料,例如 1 分 K、5 分 K、15 分 K 等。
這是整個策略疊代與驗證的核心,例如如何驗證入場優勢、如何設計停損停利,以及如何加入濾網提升勝率。
接著,我們會搭配三個主流模型的本地端開發工具來完成策略研發:
Antigravity 可以同時調用 Claude 與 Gemini,適合做大量測試與快速產出,但Gemini精準度不佳。
Codex 的優勢在於 ChatGPT 訂閱的使用額度通常較高,適合長時間的程式修改與工具開發。
Claude Code 在策略邏輯撰寫與程式理解能力上表現非常突出,是目前我最常用來生成交易策略的工具。
題外話:以我目前的實際使用經驗來看,各平台的可用額度與使用體感會變動,因此工具選擇除了能力之外,也要把額度、穩定性與成本一起考量。
 到 TradingView 參考開源策略程式碼準備回測所需的 K 棒資料
到 TradingView 參考開源策略程式碼準備回測所需的 K 棒資料至少需要兩種資料:
·1 分 K 資料:用於多時框架構驗證。
‧指定回測週期的 K 棒(例如 5 分 K、15 分 K 等):作為策略實際運行的主要週期。
蒸餾外部交易策略解析 TradingView 的策略程式碼,提取核心的進場邏輯與交易概念。
設計合理的停損與停利機制依據回測數據,建立符合該策略特性的風險控管與出場條件。
加入降低敗率的濾網條件根據 K 棒資料與市場特性,設計濾網來過濾低品質的進場訊號。
尋找最佳化參數配置對關鍵參數進行測試與調整,找出整體績效最穩定的組合。
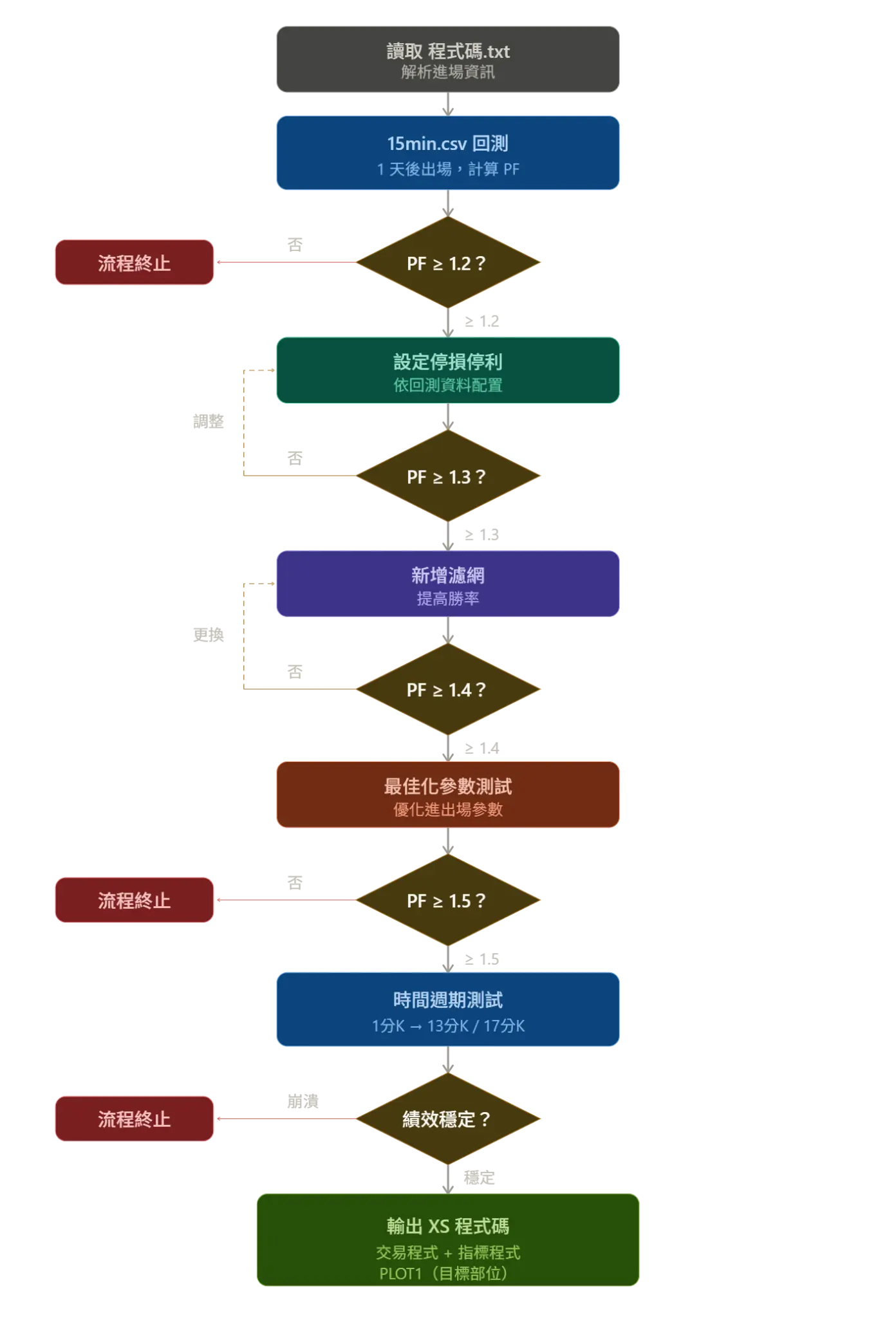
轉譯為 XQ 專用策略檔 .XS將完整策略輸出為 XQ 可執行的 .XS 檔案,內容包含:
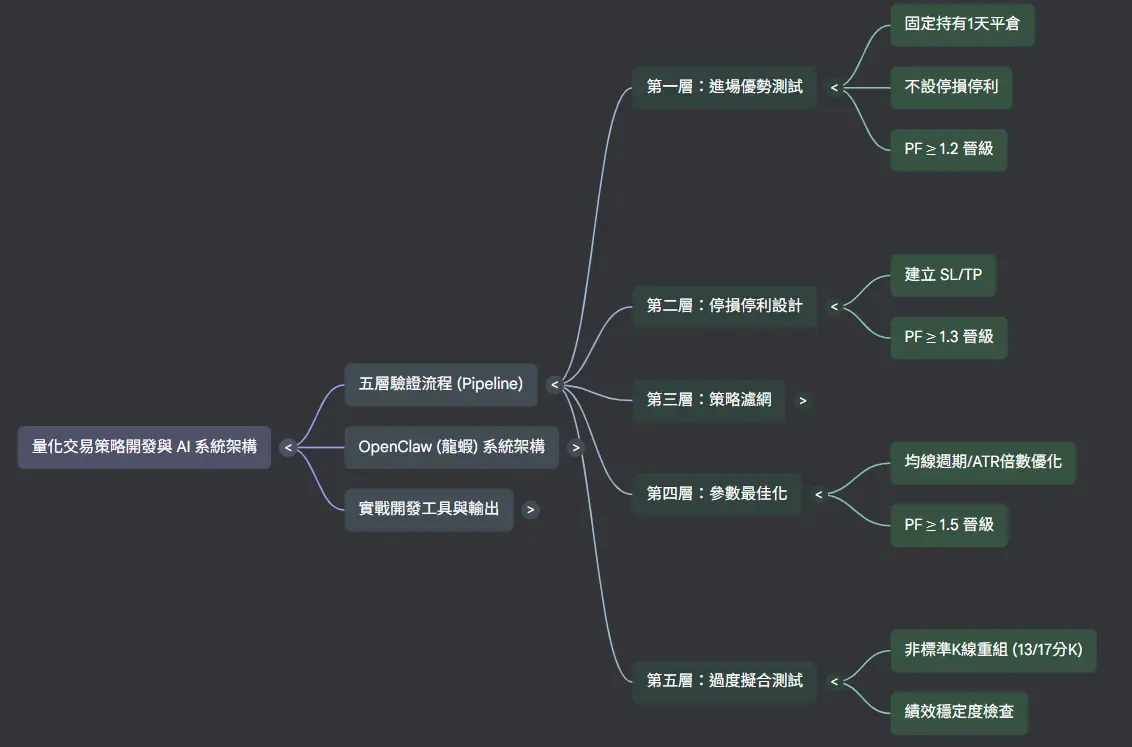
在第一階段,只驗證進場訊號本身是否具有優勢。
回測時不設置任何停損與停利,進場後固定 持有 1 天平倉,用來純粹觀察進場邏輯的品質。
此階段要求 PF(Profit Factor)至少 > 1.2,未達標則直接淘汰。
在確認進場訊號具有基本優勢後,再依據第一階段的回測數據,設計適合該策略的停損與停利機制。(這裡要注意 請 AI 把前面的持有 1 天的限制移除)目標是透過風險控管,進一步提升整體 PF 表現。
根據第二階段的回測結果,分析虧損交易的特徵,加入適當的市場濾網(例如:趨勢、波動或成交量條件)。
目的在於過濾低品質進場訊號,進一步提升策略穩定度與 PF。
對策略中的關鍵參數進行系統化測試,尋找在不同市場情境下表現最穩定的配置,
讓策略整體績效達到最佳平衡。
為避免策略過度擬合,使用 1 分 K 資料重新擬合目標週期的前後幾分鐘 K 棒,
檢查策略績效是否大幅崩潰。
若在不同時間切片下仍能維持穩定表現,代表策略具備較好的泛化能力。
這類流程設計,其實只有 AI 最適合處理與優化。
當整體邏輯與架構想清楚之後,我通常會直接把流程 交給 ChatGPT,並請它協助優化成結構清晰、可執行的提示詞。
簡單來說就是:
先把流程想清楚 → 丟給 ChatGPT → 請 AI 幫忙整理與優化提示詞。
(寫完幾篇文章後回頭補充,這個流程適用於單一策略蒸餾)
這樣可以大幅減少人工整理的時間,也能讓後續的策略研發流程更加穩定、可重複使用。
開源程式碼 Smart Money Concepts [LuxAlgo]
以下結果皆使用同一份原始策略來源、相同市場資料、相同回測期間與相同成本設定進行比較,僅比較不同模型 / 工具在策略產出上的差異。
| 模型 | PF | 3Y績效 | MDD |
|---|---|---|---|
| Claude Code (雙向) | 1.98 | 677355 | -53954 |
| Gemini 3.1 網頁版 | 1.46 | 489173 | -179139 |
| Gemini 3.1 加入Skill | -0.87 | X | X |
| ChatGPT5.4網頁版 | -0.97 | X | X |
| ChatGPT5.4加入Skill | 1.22 | 102482 | -56388 |
我過往都是使用 Gemini web PF 在 1.5 左右是極限了。
開源程式碼 Smart Money Concepts [LuxAlgo]
以下結果皆使用同一份原始策略來源、相同市場資料、相同回測期間與相同成本設定進行比較,僅比較不同模型 / 工具在策略產出上的差異。
| 模型 | PF | 3Y 績效 | MDD |
|---|---|---|---|
| Claude Code(雙向) | 1.98 | 677355 | -53954 |
| Codex(純多) | 2.07 | 271743 | -16806 |
| Antigravity | 1.35 | 390753 | -48634 |
| Gemini 3.0 cli | -0.8 | X | X |
不同模型對提示詞的理解與反應差異很大,即使我的提示詞已經先透過 ChatGPT 優化,實際套用到不同模型時,產出仍然可能明顯不同;因此我不會直接評斷誰最好、誰最差,而是會依照模型特性持續修正提示詞。
不過以目前的使用體感來說,我還是會優先選擇 Claude Code。
最後,我無法保證這些教學與範例能在每個人的電腦環境中完全重現。因為最終產出,往往會受到所使用的 AI、操作者本身的知識程度,以及提示詞細節差異的影響。
*本文主要由 AI 量化交易共同群主 阿考 撰寫,並由 Tony 與量化通團隊審核校稿後發佈。






