- 登入
- 註冊







*贊助商內容
我們在很多時候會需要用到整個上市股票和產業分類的資料表,來協助做自動化股票投資。例如,在開發選股模型時,有產業分類的資料能夠讓我們更精確地選出股票。
這個資料要去哪裡抓呢?其實證交所就有提供這個資料表了!我們只要透過爬蟲定期更新,就不會錯過新上市股票的產業分類資訊了!
首先,在證交所首頁上方列點擊「產品與服務」,並選擇「證券編碼公告」。如下方截圖。
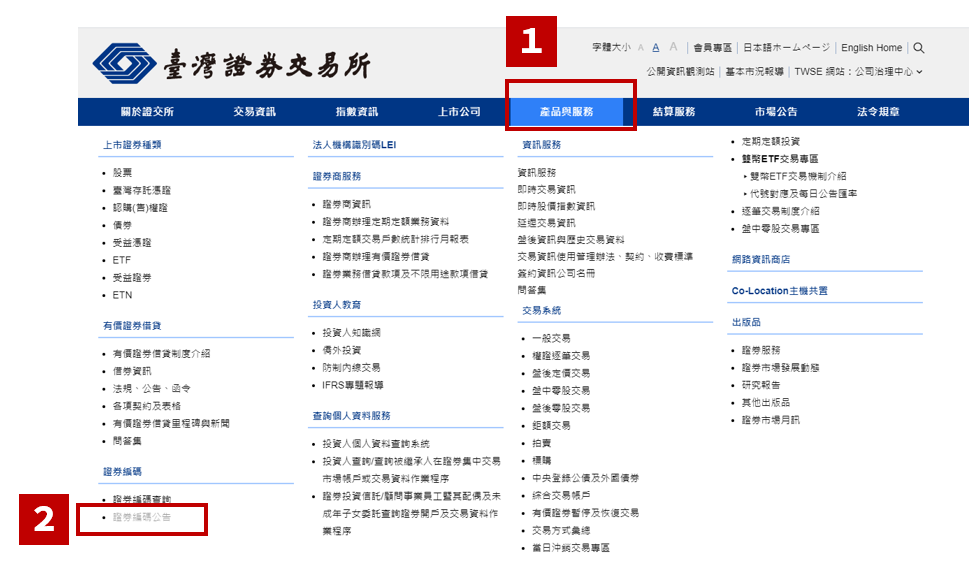
再來,點擊「本國上市證券國際證券辨識號碼一覽表」右方的連結。如下圖。
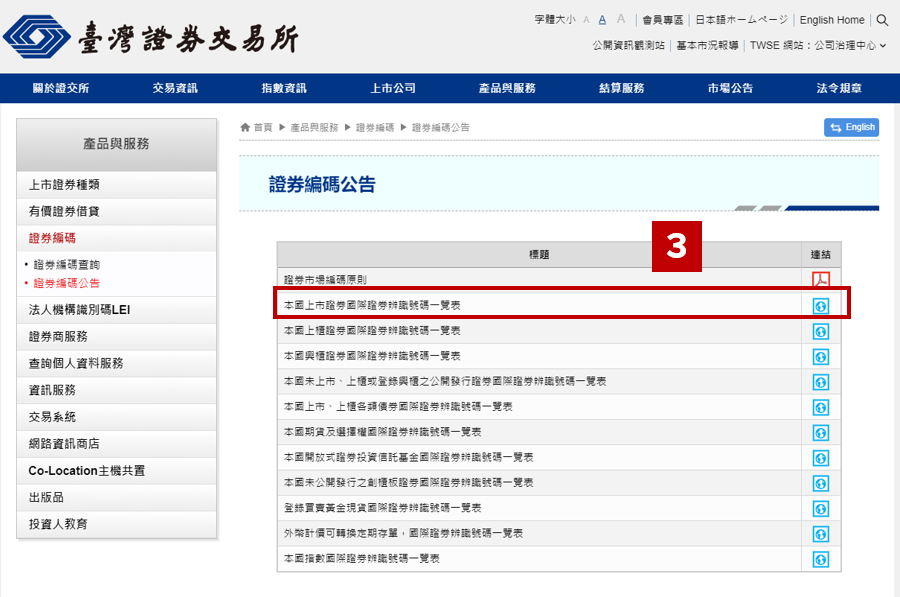
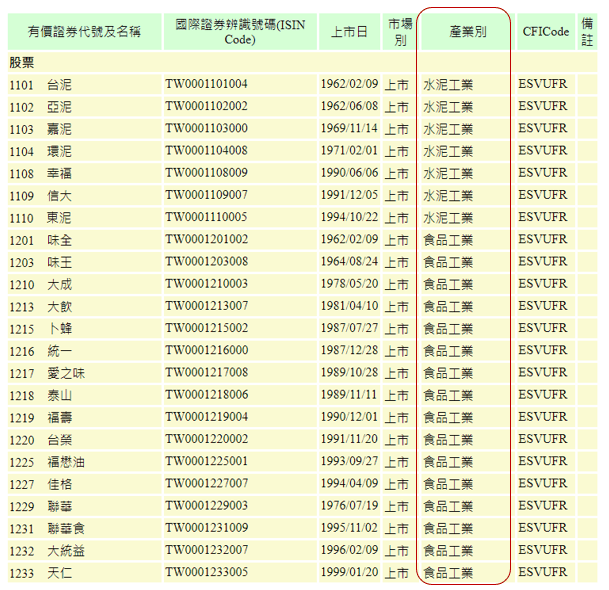
於是,我們就能看到我們想要的那份資料表了。如下圖所示。
網址為:https://isin.twse.com.tw/isin/C_public.jsp?strMode=2。先記起來,在後續的爬蟲會用上。
現在,我們知道網址了,就用最經典的 requests 和 BeautifulSoup 套件完成這項爬蟲任務吧!
首先,我們先 import 這兩個套件:
import requests
from bs4 import BeautifulSoup再來,我們透過 requests 套件的 get 方法來訪問這個頁面,把回傳結果存進 res。
url = "https://isin.twse.com.tw/isin/C_public.jsp?strMode=2"
res = requests.get(url)緊接著,我們使用 BeautifulSoup 來解析這個回傳內容。我們會發現這個表格即是由典型的 tr 和 td 所構成:每一個 tr 標籤中的內容為一行資訊,每一個 td 標籤中的內容為該行中每一格所包含的資訊。因此,我們先依據 tr 做 findAll,這樣後續在根據 tr 做 for 迴圈時,即是一行一行把資料取出來的意思。
而在下方程式碼中,我們把 tr 每一行取出來的資料,再用 td 去解析,就可以得到,並且使用 get_text() 把每一個 td 標籤中的值取出來,就能萃取出該行包含每一個值的 list 了,也就是程式碼中的 data。
但是從上面的截圖,我們可以知道,蘊含有用資訊的 data 必須要有 7 個值。因此,我們加上一個資料長度的判定,過濾掉無用資訊。
soup = BeautifulSoup(res.text, "lxml")
tr = soup.findAll('tr')
tds = []
for raw in tr:
data = [td.get_text() for td in raw.findAll("td")]
if len(data) == 7:
tds.append(data)如此一來,這個表格就完整地存下來了!我們可以試著用 pd.DataFrame 印出來看看。
import pandas as pd
pd.DataFrame(tds[1:],columns=tds[0])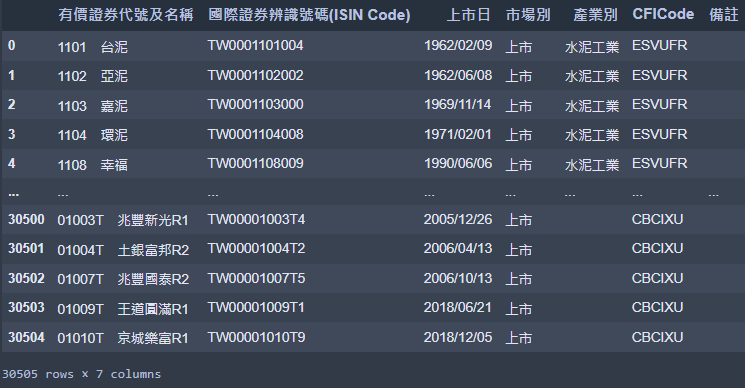
看來,不僅是上市股票,連權證代碼都一起爬下來了。進一步的整理,以及把證券代碼從「有價證券代碼及名稱」列解析出來,就靠聰明的讀者自行練習囉!
至於如何應用產業分類資料在選股模型上,有興趣的同學可以參考一下 Python 選股模型課程,有完整的解說!






