- 登入
- 註冊





*贊助商內容

我們在進行回測時,最先遇到的問題往往是:除權息的跳空該怎麼處理?不妥善處理的話,有偏差的回測結果會導致數據完全不具參考性。因此,為求回測結果準確,我們需要標的配息時間和股息金額的歷史資料。
本篇接下來就一步一步帶大家完成 ETF 配息歷史資料爬蟲的實作吧!
首先,我們使用查詢 ETF 相關資料常用的網站 MoneyDJ,在每檔 ETF 資訊的頁面中,其中有一個頁籤叫做「配息紀錄」,其中就包含了我們需要的配息歷史表格!如下方截圖,或是從下方連結進入 0050 (台灣 50 ETF)的配息紀錄頁面。
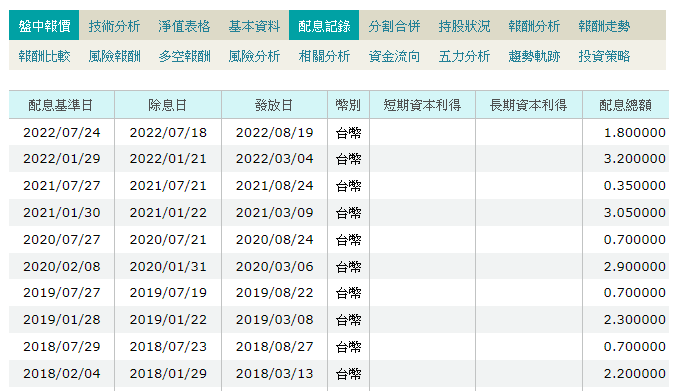
台灣 50 ETF的配息紀錄頁面:https://www.moneydj.com/ETF/X/Basic/Basic0005.xdjhtm?etfid=0050.TW
在切換幾檔 ETF 之後,我們發現不同 ETF 的網址只差在 etfid 後的值。這樣的話一切都很單純了!代表我們可以建立一個函數,只要傳入不同的 ETF股票編碼,就能爬取到它的配息歷史數據了!
我們現在有網址了,那接下來解說一下爬取方式吧!
首先,我們 import 爬蟲及資料整理的常用套件。相關套件的基礎操作教學請詳見量化通其他文章。
import requests
import numpy as np
import pandas as pd from bs4
import BeautifulSoup接著,為了方便重複使用爬蟲程式碼,如先前所述,我們確定了網址的命名規則。因此,下面我們展示設計完成的函數直接進行解說:
def get_dividend_list(symbol):
div_url = f'https://www.moneydj.com/ETF/X/Basic/Basic0005.xdjhtm?etfid={symbol}.TW'
r = requests.get(div_url)
soup = BeautifulSoup(r.text, "lxml")
table = soup.findAll("table", class_ = "datalist")[0]
list_rows = []
rows = table.find_all('tr')
for row in rows:
row_td = [i.text for i in row.find_all('td')]
if len(row_td)>1:
list_rows.append(np.array(row_td)[[1,2,6]])
df = pd.DataFrame(list_rows, columns =
['ex_div_date','pay_date','div_amount'] )
df['symbol_id'] = [symbol] * len(df)
return df為什麼要另外製作 ETF 代碼的 colomn 呢?試想一下,如果我們現在有 200 個 ETF 的配息歷史資料需要爬取,搭配 ETF 代碼的 colomn 後,我們就能夠把所有資料整併進一個 pd.DataFrame ,方便管理和後續取用。
以 0050 為例,我們試著運行看看這個爬蟲程式:
dividend = get_dividend_list(“0050”)
print(dividend)





