- 登入
- 註冊





*贊助商內容

既然要談到資料蒐集,爬蟲勢必就是得好好學習的一環,
一旦討論到爬蟲,就不得不談到網頁架構囉!
有些人會問說:「那爬蟲與網頁架構有啥關聯呢?」
而答案其實就是因為「爬蟲說穿了就是將網站上的資料擷取下來。」
這樣聽起來可能有點繞口,把爬蟲想成當我們想要網站上的一篇文章內容、一些表格資料,甚至是某張圖片,這時我們會怎麼做來將我們想要的內容存下來呢?
是不是肯定就是複製貼上到WORD?或是對圖片按右鍵去另存圖片呢?
是的,爬蟲就是一個讓程式做跟人們一模一樣的事情,只是說人們判斷想要的資訊很簡單(畢竟是聰明的人腦嘛~)
但程式並沒有那麼聰明,所以這時候只能夠讓人們先告訴程式我想要那些資料、那些資料該長怎樣,存下來時的排版或是分類方式該是如何等等等,讓程式可以照我們的需求乖乖把事情做好呦!
如下圖,網頁一般分為前端(使用者接觸的到的)與後端(使用者接觸不到的)。
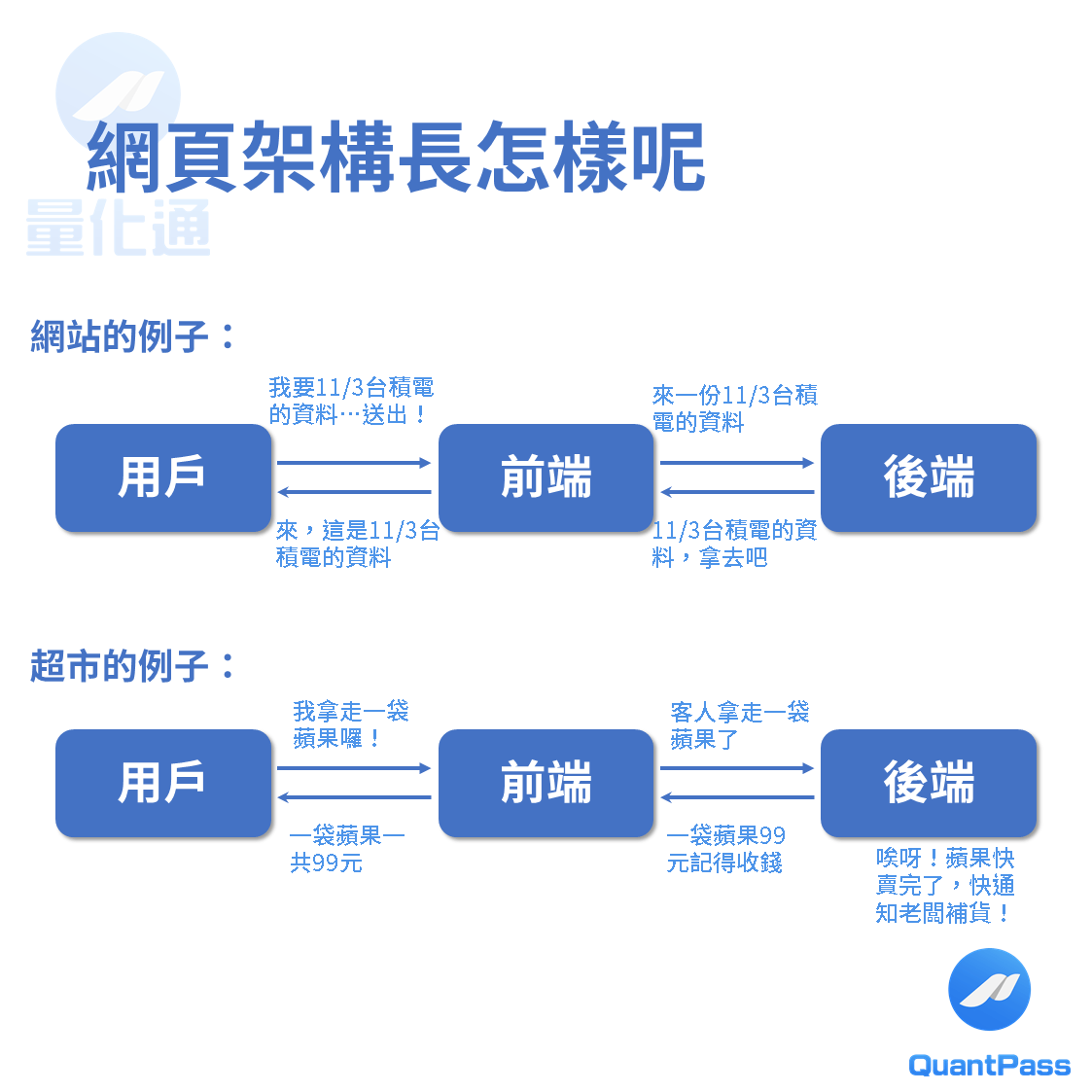
把它想成超市就很好理解了,網頁的後端如同超市的營運管理系統,比如說如何決定牛奶多少錢,以及後面物流該多久進一次貨、怎麼計算一天營業額等,都是屬於管理系統的管轄範圍。
回過頭來,網站後端就是資料庫、程式該怎麼運作等「用戶從介面看不到的功能設計」。
而前端就像是超市中的牛奶該放在哪一櫃、櫃台該在設置在哪邊、動線怎麼規劃、乃至於讓客戶覺得超市美輪美奐想坐下來休息等等與「客戶可以第一線接觸到的使用者設計」。
所以當我們使用爬蟲來做資料擷取時,就像是我們上網去找資料想把它存下來一樣,所以基本上其實就是在跟網頁的前端互動囉!
首先我們要先認識前端基本組成,以剛的超市為例:
(1) 以超市為例:必需要有防火設備、出入口、燈光、人員、商品等最基本的設備。
(2) 以網頁為例:看到 「image」 就表示這是張圖片等原則型的標準內容。
(1) 以超市為例:改變燈光色彩、地板材質、員工服裝、桌椅配色等等。
(2) 以網頁為例:網頁顏色、文字顏色、旋轉、模糊等等美感進階設計。
(1) 以超市為例:ibon可以取票、結帳可以掃載具、刷悠遊卡等等。
(2) 以網頁為例:按按鈕可以顯示文章、在網頁上輸入日期可以查詢車班等等。
爬蟲,就是基本上針對這三大項內容進行資料蒐集囉!以上就是大概在爬蟲開始前,必須要知道的網頁內容。






