- 登入
- 註冊





*贊助商內容

Cookie 是您造訪的網站所建立的檔案。這些檔案透過儲存瀏覽資訊,為您提供更便利的線上體驗。網站可以利用 Cookie 進行以下操作:
–GOOGLE
1. 保持登入狀態
2. 記住您的網站偏好設定
3. 提供與您所在地相關的內容
有時候我們需要爬取登入後才能訪問的頁面,這時就需要藉助 cookie 來完成模擬登入和會話的維持了。
那麼伺服器是如何知道我們已經登錄了呢?當用戶首次發送請求時,伺服器端一般會生成並存儲一小段信息,包含在response數據裡。
如果這一小段信息存儲在客戶端(瀏覽器或硬碟),我們稱之為cookie。
如果這一小段信息存儲在伺服器端,我們稱之為session(會話)。
這樣當用戶下次發送請求到不同頁面時,請求自動會帶上cookie,這樣伺服器就知道用戶之前已經登入訪問過了。
以下就是我們這次的範例目標:
https://www.ptt.cc/bbs/Gossiping/index.html
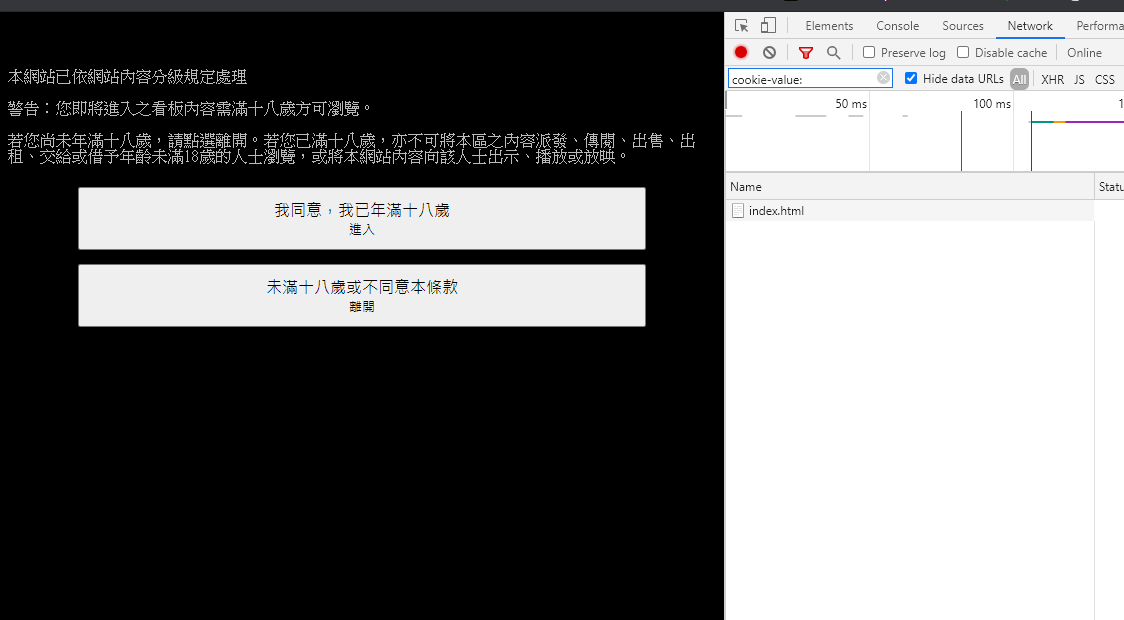
但因為在使用python進去 18禁 頁面時,
是會跳出條件選擇的,所以沒有帶cookie時,是爬不到頁面的哦!
那麼就直接開始吧!
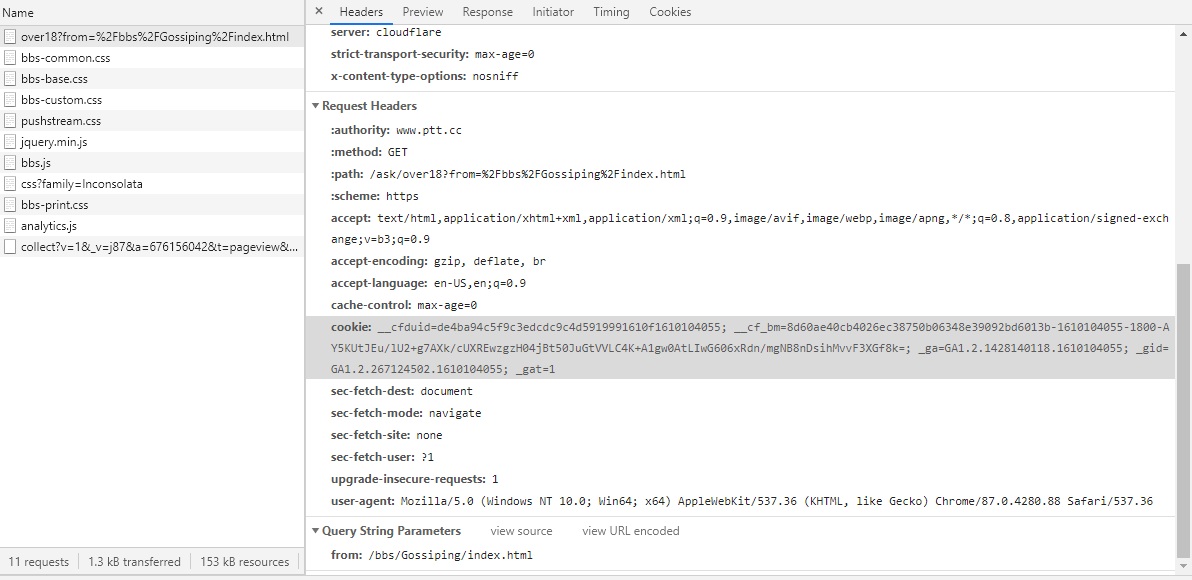
先打開第一層的 F12 看一下目前的 cookie:
在尚未點選滿18歲時的 cookie 長相如下圖。
這是點選後進去的長相。
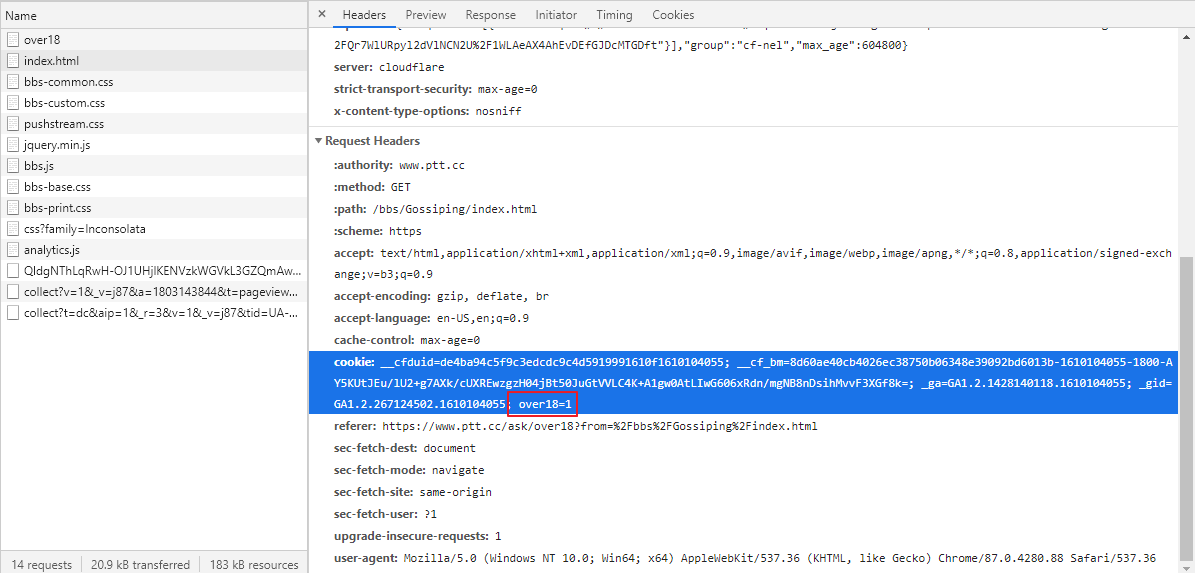
所以我們知道就是差在 over18 = 1 這個內容,那就直接把它加進去即可囉!
首先我們先呼叫基本套件,並把目標網址先設定好:
import requests
from bs4 import BeautifulSoup
url = ‘https://www.ptt.cc/bbs/Gossiping/index.html’
再來就是把 header 做好,並且將剛剛的 over18 = 1 放進去:
headers = {
“cookie”: “over18=1”,
“User-Agent”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36″0
}
最後就像是一般爬蟲一樣,將對應的丟進去即可囉!
r = requests.get(url, headers=headers).content
soup = BeautifulSoup(r, “html.parser”)
text_titles = soup.find_all(“div”, class_=”title”)
for title in text_titles:
if title.a != None:
print(title.a.string)
那結果就會如下圖,這就是帶cookie後,相對應爬出來的內容囉!
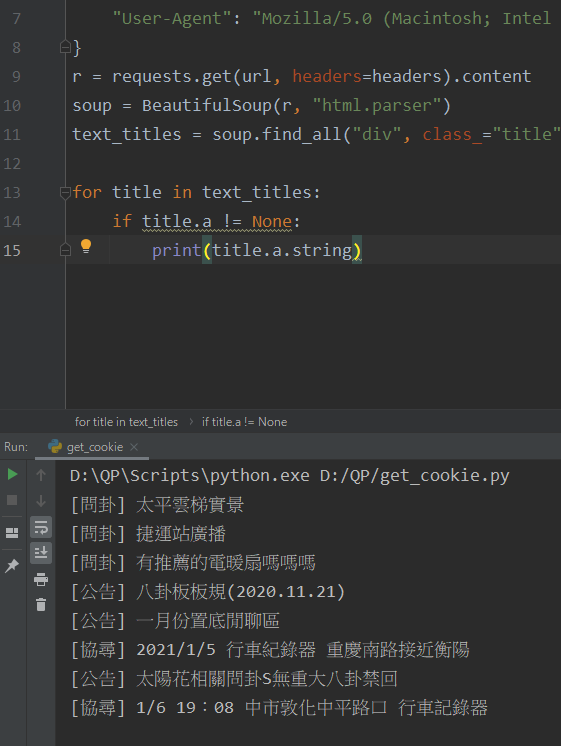
那這篇文大概就介紹到這邊,因為 cookie 的使用方式很多元,
會需要考量很多種狀況,所以如果各位真的有興趣,
我再找時間寫其他相關的內容囉!
那程式碼我附在底下,感謝大家!
完整程式碼如下:
import requests
from bs4 import BeautifulSoup
url = ‘https://www.ptt.cc/bbs/Gossiping/index.html’
headers = {
“cookie”: “over18=1”,
“User-Agent”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36″0
}
r = requests.get(url, headers=headers).content
soup = BeautifulSoup(r, “html.parser”)
text_titles = soup.find_all(“div”, class_=”title”)
for title in text_titles:
if title.a != None:
print(title.a.string)






